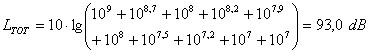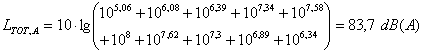ACUSTICA PSICOFISICA
Misura
dei fenomeni acustici in decibel
I fenomeni acustici
consistono in fenomeni oscillatori della materia; quindi, contrariamente alle
onde elettromagnetiche non si propagano nel vuoto e necessitano per la loro
propagazione di un mezzo elastico.
L’orecchio umano percepisce
questi fenomeni per un intervallo di frequenze che va dai 20 Hz e i 20 kHz. Le
oscillazioni non percepibili che si trovano al di sopra dei 20 kHz vengono
chiamate ultrasuoni, mentre al di sotto dei 20 Hz infrasuoni.
Il suono si propaga nel
mezzo elastico tramite onde di pressione. La sorgente sonora, cioè un corpo in
vibrazione, trasmette sollecitazioni di pressione al mezzo, mediante una legge
matematica in funzione del tempo. Le particelle del mezzo, sollecitate,
oscillano attorno alla loro posizione di riposo, dando origine a trasformazioni
della loro energia potenziale elastica in energia cinetica e viceversa. Nel
mezzo di propagazione si ha quindi una perturbazione di pressione, la cui
velocità è chiamata velocità del suono.
I fenomeni acustici vengono
espressi mediante la scala logaritmica dei decibel (dB), che fa riferimento
alla pressione acustica; quest’ultima è la differenza tra la pressione p(t)
presente nell’istante t e la pressione statica che ci sarebbe nello stesso
punto e nello stesso istante t in assenza del passaggio dell’onda sonora. Il
livello di pressione acustica L in dB al di sopra di un livello zero di
riferimento, che corrisponde alla pressione di riferimento P0, è dato dalla relazione:
L
= 20 log10( P / P0 )
dove P è la pressione
acustica.
La scala dei decibel tiene
quindi conto della percezione logaritmica che l’orecchio umano ha del suono e
che è caratteristica di tutte le sensazioni umane, le quali sono proporzionali
al logaritmo dello stimolo.
La
sensazione uditiva
I fenomeni acustici sono
caratterizzati da due grandezze: pressione acustica e frequenza. La prima
dipende dalla pressione esercitata dall’onda sonora sulle particelle del mezzo
di propagazione, la seconda dal numero d’oscillazioni che avvengono al
passaggio dell’onda in un secondo.
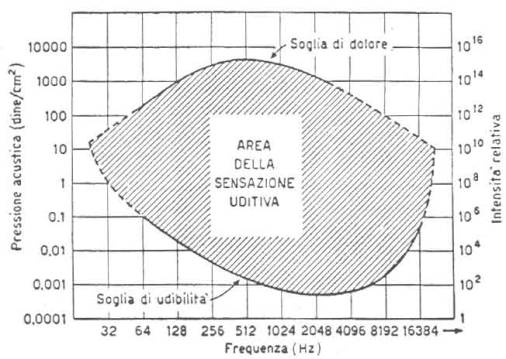
fig. 1
Il grafico (fig. 1) mette
in relazione queste due grandezze e delimita l’area della sensazione uditiva
che racchiude tutti i suoni percepibili dall’udito umano; superiormente essa è
limitata da una curva detta soglia del dolore e inferiormente dalla curva
chiamata soglia d’udibilità.
L’audiogramma
normale di Fletcher e Munson
L’audiogramma normale di Fletcher
e Munson (fig. 2) fornisce dati sul comportamento dell’udito umano nel caso di
suoni puri con riferimento all’intensità soggettiva; quest’ultima è legata al
livello di pressione e alla frequenza dell’onda sonora. L’audiogramma è il
frutto di studi compiuti su un gran numero di individui aventi un udito normale
e privo di difetti. E’ limitato inferiormente da una curva che corrisponde alla
soglia di udibilità e superiormente da tre tipi di curve dette: soglia del
disturbo, soglia del dolore e soglia del danno uditivo che naturalmente non è
determinabile sperimentalmente. La zona tra la soglia di udibilità e quella del
dolore è detta area di udibilità normale; le due soglie tendono inoltre a
congiungersi ai due estremi della banda delle frequenze udibili; l’estremo
inferiore della banda si trova ad una frequenza di 16÷20 Hz, quello superiore a
16 kHz. Al di sopra della banda vi è la banda degli ultrasuoni, al di sotto
quella degli infrasuoni.
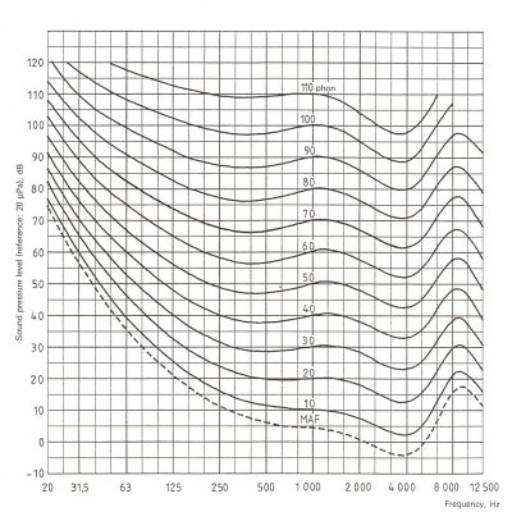
fig. 2
Per tracciare l’audiogramma sono stati effettuati dei confronti tra una serie di toni puri, sparsi in tutta la banda delle frequenze, e un tono puro di riferimento con frequenza di 1000 Hz. Mantenendo fisso il livello di pressione del tono di riferimento e modificando quello degli altri toni puri fino a raggiungere la condizione di isointensità soggettiva, e misurando per tutti i toni puri i valori del livello di pressione che fanno capo alla condizione di isointensità soggettiva, è possibile tracciare sull’audiogramma i punti sperimentali corrispondenti. Tramite un’interpolazione è possibile disegnare una curva dove è costante il livello di intensità di sensazione; questa curva è detta isofonica. Ogni curva fornisce un valore diverso del livello di intensità soggettiva, la cui unità di misura è il phon.
Le isofoniche sono graficamente abbastanza simili tra loro ma non sono mai sovrapponibili e la loro forma mostra la forte non linearità che caratterizza l’udito umano. Dall’audiogramma si nota come l’orecchio umano sia più sensibile alle medie frequenze fra qualche centinaio e qualche migliaio di Hz; ciò dipende dalla configurazione strutturale del padiglione auricolare che amplifica specificamente i suoni solo per una fascia di valori delle frequenze.
La scala dei Phon è caduta
in disuso per due motivi, uno di tipo pratico e l’altro di natura teorica: il
primo consiste nella difficoltà a lavorare con curve complicate, non
determinabili da un'unica legge e difficilmente utilizzabili con una tecnologia
di tipo analogico che rendeva necessaria addirittura una conversione a mano dei
dati; il secondo motivo prende in considerazione il fatto che questa scala
utilizza solo suoni puri, cioè sinusoidi perfette, diretti frontalmente
all’orecchio umano con perdita della tridimensionalità del campo sonoro.
Il sistema uditivo
Il sistema uditivo dell’uomo può essere sintetizzato in tre parti: orecchi esterno, orecchio medio e orecchio interno.
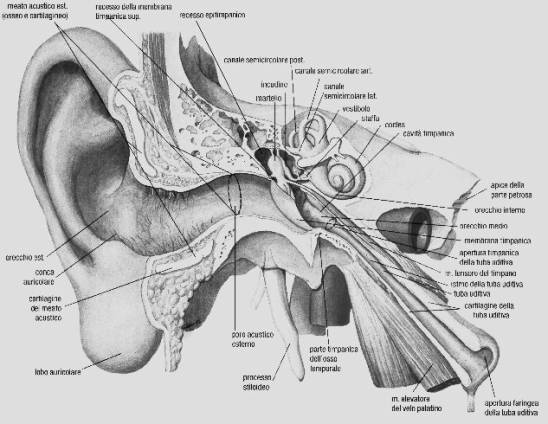
fig. 3
L’orecchio esterno, oltre al padiglione auricolare, comprende un condotto, detto canale auricolare, alla cui estremità si trova il timpano, membrana elastica e sottile, ma robusta; questa divide orecchio esterno e medio, e funziona inoltre da barriera, poiché non permette né all’acqua né all’aria di entrare all’interno dell’orecchio.
L’orecchio medio si trova racchiuso nella cassa timpanica, cavità ossea del cranio, che contiene tre ossicini (martello, incudine e staffa (fig. 4)), i quali hanno la funzione di trasmettere le vibrazioni prodotte dai suoni nella zona più interna dell’orecchio.
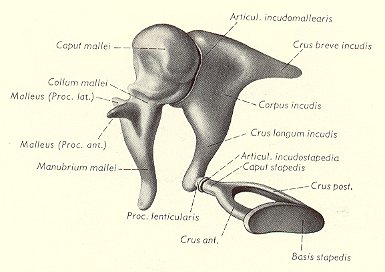
fig. 4
La cassa timpanica è inoltre messa a contatto con le retrocavità nasali tramite la tromba di Eustachio. Orecchio medio ed interno sono separati da un’altra membrana detta finestra ovale, la quale è a contatto con la staffa. Il compito degli ossicini è trasformare la forma ma non il contenuto del segnale sonoro per non perderne la qualità quando nell’orecchio interno il segnale deve attraversare l’endolinfa, liquido dotato di una propria impedenza acustica.
L’orecchio interno è costituito dalla coclea e dal labirinto (fig. 5).
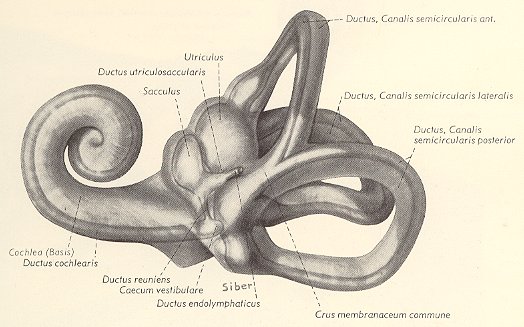
fig. 5
La coclea, che è il vero organo uditivo, è un condotto formato da due canali che ha forma di chiocciola. Questi canali sono divisi da una membrana detta basale e prendono il nome di canale vestibolare e timpanico (fig. 6).
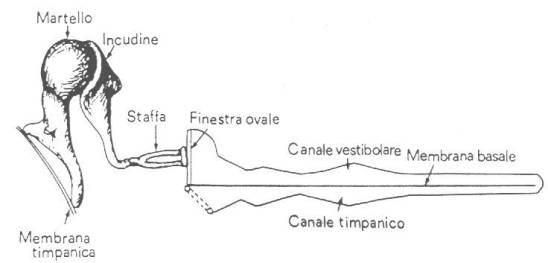
fig. 6
Il segnale sonoro percorre interamente il primo per poi passare nel secondo; al suo passaggio si verifica tra i due condotti una differenza di pressione che viene recepita dalle cellule cigliate che si trovano sulla membrana ed ospitano terminazioni nervose. Inoltre lo spessore della membrana aumenta all’allontanarsi dalla finestra ovale diventando però più molle. Questa struttura permette di distinguere le varie frequenze: i suoni ad alta frequenza sono registrati dalla prima porzione della membrana, mentre le più basse frequenze dall’ultima. Proprio perché le frequenze sono separate, un danno all’udito a livello delle terminazioni nervose che si trovano sulla membrana basale non pregiudica la ricezione totale dei suoni ma solo quella che avviene alle frequenze corrispondenti alle terminazioni danneggiate.
Perdita
dell’udito
I danni al sistema uditivo umano possono essere temporanei oppure permanenti.Un danno temporaneo può comparire con l’esposizione per alcune ore dell’organo uditivo a livelli sonori alti; può causare nausea, perdita dell’equilibrio, labirintite ed è dovuto alla maggiore sforzo meccanico che l’organo deve compiere. Si hanno danni permanenti specialmente per l’esposizione, prolungata negli anni, a suoni di livello medio alto, come spesso avviene in certi ambienti di lavoro.
Il grafico seguente mette in relazione la perdita in decibel rispetto alle varie frequenze, secondo il periodo di esposizione prolungata a livelli medio alti.
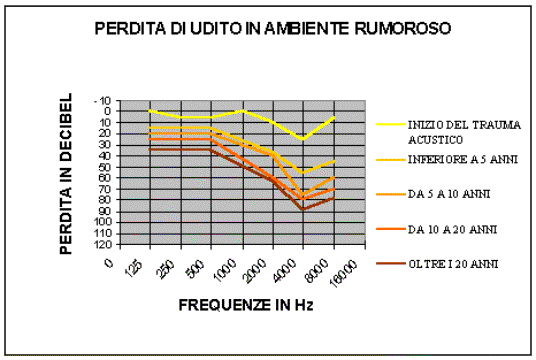
fig. 7
Dal grafico di fig. 7 si può vedere come l’esposizione prolungata a suoni con un livello di 90 dB arrechi più danni intorno ai 4000 Hz. La sensibilità del sistema uditivo umano è infatti maggiore tra i 2000 e i 4000 Hz, poiché in questa banda di frequenze vengono emesse le consonanti. Una persona con un danno uditivo riporta quindi difficoltà a percepire le consonanti, mentre sente bene le vocali che hanno frequenze intorno ai 400 Hz. Il risultato è che la persona con udito leso sente che le si sta parlando, ma ha difficoltà a capire quello che le viene detto.
Esempio
L’esempio seguente mostra come si possa ridurre l’inquinamento acustico spostando l’energia in gioco ad una frequenza più bassa.
Una ventola formata da
quattro pale lavora a 3000 G/min e quindi ad una frequenza f pari a 200 Hz.
Infatti f = 50 (G/sec) * 4 (n°pale) = 200 (Hz). Una ventola di questo tipo
produce un inquinamento acustico di 81 dB(A) @ 90 dB. Per diminuire i dB(A) bisogna diminuire la
frequenza; volendo mantenere costanti i 3000 G/min non resta che diminuire il
numero delle pale. Utilizzando due pale, più grosse delle precedenti, posso
ridurre il rumore prodotto a 71 dB(A).
Curve di
ponderazione
Lo strumento standard utilizzato per compiere le misure fonometriche è il misuratore di livello sonoro normalizzato, chiamato comunemente fonometro.
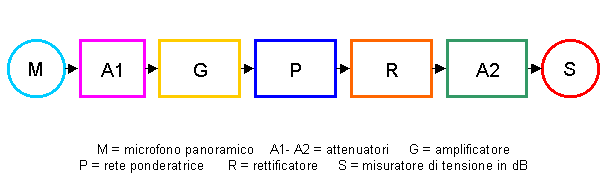 fig. 8
fig. 8
Da una schematizzazione a blocchi del fonometro (fig. 8) vediamo che il segnale dal microfono panoramico, attraverso un attenuatore, arriva ad un amplificatore e poi passa attraverso una rete ponderatrice. Le reti ponderatrici del fonometro sono selezionate da un commutatore ed il loro incarico è quello di assegnare allo strumento una curva di risposta affinché essa riproduca il corrispondente comportamento dell’udito. Una curva di ponderazione, che è in pratica una isofonica ribaltata, rappresenta la caratteristica sensibilità-frequenza. Dopo essere stato ponderato il segnale viene inviato per mezzo di un rettificatore e di un attenuatore ad uno strumento indicatore, che è tarato in dB.
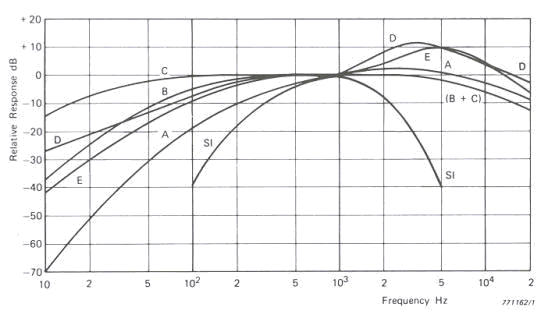
fig. 9
Vi sono varie curve di ponderazione (fig. 9) , anche se quella comunemente usata è la curva di ponderazione A che è risultata quella meglio correlata con gli effetti indesiderati dei rumori da valutare. La curva A corrisponde alla isofonica di 40 phon dell’audiogramma normale di Fletcher e Munson, la B a quella di 70 phon, mentre la C a quella di 100 phon. La curva D è utilizzata per la valutazione della rumorosità del traffico aereo. Il fonometro non garantisce una approssimazione precisa nel caso di suoni a spettro complesso; il gap tra il livello sonoro restituito dal fonometro e il livello in phon supera spesso le 10 unità logaritmiche. Lo scopo che si raggiunge con la ponderazione è comunque quello di convertire in scala logaritmica il segnale elaborato dagli strumenti in forma lineare.
Filtri passa-banda
Per effettuare l’analisi in frequenza può
venire utilizzato un banco di filtri passa-banda. Questo metodo consiste nello
studiare il segnale sonoro a frequenze separate: ogni singolo filtro del banco
è infatti costruito in modo da permettere il passaggio delle sole frequenze che
fanno parte di un determinato intervallo. Fornendo ogni filtro di un voltmetro
si può quindi misurare il livello di ogni intervallo di frequenze. Se il nostro
filtro fosse ideale la curva del guadagno (fig. 10) dovrebbe essere equivalente
ad un impulso rettangolare mentre nella realtà i fronti di salita e discesa non
raggiungono mai la perfetta perpendicolarità rispetto all’asse delle frequenze
per limiti tecnologici (fig. 10).
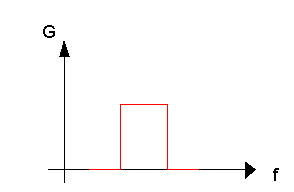
fig. 10
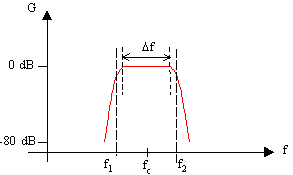
fig. 11
Il grafico (fig. 11) che rappresenta il guadagno ipotetico di un filtro reale è costituito da una parte centrale in cui esso vale costantemente 0 dB che prende il nome di banda efficace (Df), che è compresa tra le due frequenze di taglio f1 e f2 posizionate a metà energia rispetto alla banda passante; alle due estremità di questa banda vi sono due zone in cui il guadagno è trascurabile che devono comunque avere una pendenza variabile entro una determinata tolleranza definita dall’I.E.C.(organizzazione per la definizione degli standard delle misure acustiche). Il guadagno corrispondente a f1 e f2 vale -3 dB. fc è detta frequenza di centro-banda e naturalmente il guadagno equivale a 0 dB. I principali spettri per bande sono: quello a bande costanti, caratterizzato dalla medesima ampiezza di tutte le bande, e quello a bande percentuali costanti, dove ogni banda è il doppio della precedente. Spettri a bande percentuali costanti sono quelli a banda d’ottava. L’ottava, che corrisponde all’ottava musicale, è delimitata tra due frequenze f1 e f2 tali che il rapporto f1/f2 sia uguale a 2 (f1<f2); sono valide per essa le seguenti relazioni:
![]()
L’ottava è una banda piuttosto larga e in talune applicazioni è necessario suddividere la banda d’ottava in bande sottomultiple; i filtri di questo tipo sono chiamati a frazione d’ottava. La suddivisione più nota è quella di 1/3 d’ottava, ma sono comuni anche filtri di 1/6, 1/12, 1/24 d’ottava. Ogni filtro di questo tipo dovrà verificare che il rapporto tra la differenza delle frequenze f2 e f1 e la frequenza di centro-banda sia equivalente ad un valore costante.
![]()
Questo valore costante per i filtri d’ottava equivale a:
![]()
La frequenza massima di un filtro risulta uguale alla minima di quello seguente. Se prendiamo in considerazione filtri a 1/12 d’ottava il rapporto tra f1 e f2 è il seguente:
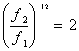
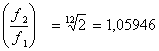
Il rapporto tra f1 e f2
nel caso di un filtro a 1/3 d’ottava è:
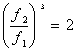
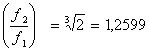
I filtri a 1/3 d’ottava sono i più utilizzati poiché meglio si rapportano al sistema uditivo umano, specialmente per frequenze sopra i 600 Hz; al di sotto di questo valore non è infatti possibile riprodurre la risoluzione dell’udito umano. La seguente tabella mostra che con dieci filtri d’ottava è possibile ricoprire l’intero spettro delle frequenze udibili. Ciascun filtro ha frequenza di centro banda doppia di quella del filtro precedente. L’insieme dei dieci filtri copre le frequenze tra i 20 Hz e i 20 kHz.
|
fc1 |
fc2 |
fc3 |
fc4 |
fc5 |
fc6 |
fc7 |
fc8 |
fc9 |
fc10 |
|
31,5 Hz |
63 Hz |
125 Hz |
250 Hz |
500 Hz |
1 kHz |
2 kHz |
4 kHz |
8 kHz |
16 kHz |
Un banco di filtri a 1/3 d’ottava sarà quindi formato da trenta filtri mentre uno a 1/12 d’ottava da ben 120 filtri.
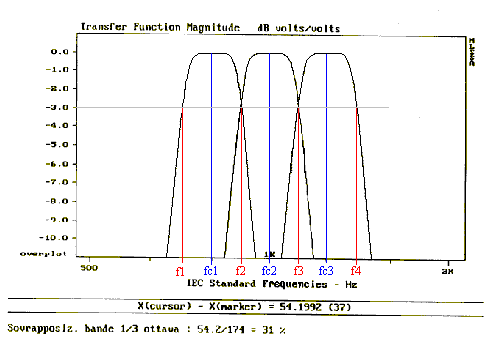
fig. 12
I filtri reali non possono separare alla perfezione le frequenze. La probabilità che un suono puro cada nella zona in cui due filtri ad 1/3 d’ottava (fig. 12) si sovrappongono è alta; in questo caso la sovrapposizione è del 31%. Alle frequenze f2 e f3 riportate in figura ad esempio lo spettro rileva energia sia nella banda inferiore sia in quella superiore.
Rappresentazioni
spettrali
Uno stesso segnale può essere rappresentato tramite vari tipi di spettri, differenti per tipo di banda o per scala dell’asse delle frequenze. Dal punto di vista grafico gli spettri di uno stesso segnale risultano molto diversi l’uno dall’altro.
Dall’analisi dello stesso segnale per bande percentuali costanti in terzi d’ottava prima con asse delle frequenze in scala logaritmica (fig. 13) e poi lineare (fig. 14 ) si vede che nel primo caso i terzi rimangono costanti, mentre nel secondo questi si allargano all’aumentare della frequenza; nel primo grafico il segnale appare abbastanza livellato, mentre nel secondo diminuisce d’altezza con l’aumento della frequenza. In entrambi i casi il picco di 87.3 dB si trova alla frequenza di 1982,1286 Hz. A testimonianza che il segnale studiato è il medesimo.
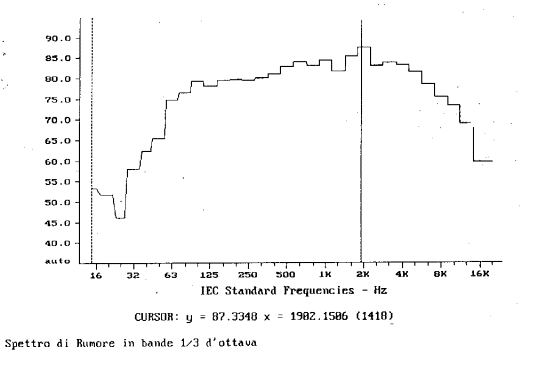
fig.13
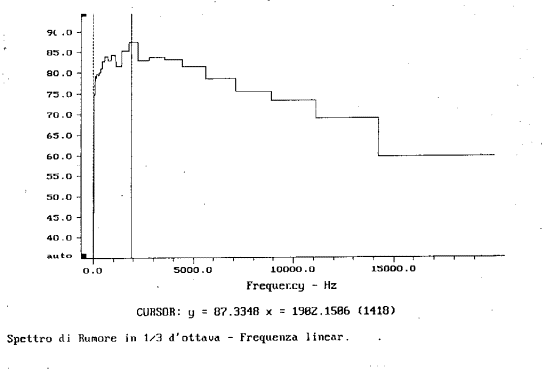
fig. 14
I seguenti grafici mostrano l’analisi in frequenza dello stesso segnale in banda stretta con asse delle frequenze prima in scala logaritmica (fig. 15 ) e dopo lineare (fig. 16 ). Anche questa volta il grafico in scala lineare tende ad essere livellato, mentre quello in scala lineare decresce in altezza. Con l’analisi in banda stretta il picco scende a 66.87. L’analisi in banda stretta restituisce frequenze in media più basse rispetto all’analisi in terzi d’ottava; essa attenua i livelli a più alte frequenze, mentre amplifica quelli a frequenze minori.
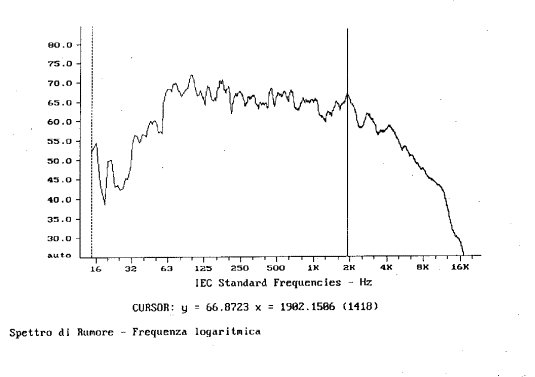
fig. 15
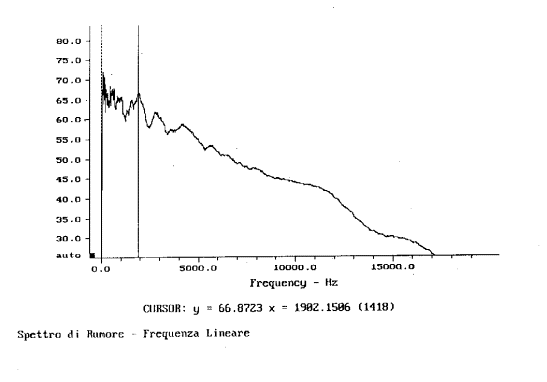
fig. 16
Esercizio
Data la seguente tabella calcolare il livello totale in dB e in dB(A).
|
frequenza |
dB |
A |
dB(A) |
|
31,3 |
90 |
-39,4 |
50,6 |
|
63 |
87 |
-26,2 |
60,8 |
|
125 |
80 |
-16,1 |
63,9 |
|
250 |
82 |
-8,6 |
73,4 |
|
500 |
79 |
-3,2 |
75,8 |
|
1000 |
80 |
0 |
80 |
|
2000 |
75 |
1,2 |
76,2 |
|
4000 |
72 |
1 |
73 |
|
8000 |
70 |
-1,1 |
68,9 |
|
16000 |
70 |
-6,6 |
63,4 |