Acustica psicofisica
Presentazione:
Vedremo come funziona il nostro sistema uditivo, scoprendo che esso reagisce secondo matematiche diverse da quelle di uno strumento elettronico, in quanto come per tutte le percezioni umane, la sensazione uditiva non è proporzionale allo stimolo, ma al suo logaritmo.
Come è fatto e come funziona il sistema uditivo umano
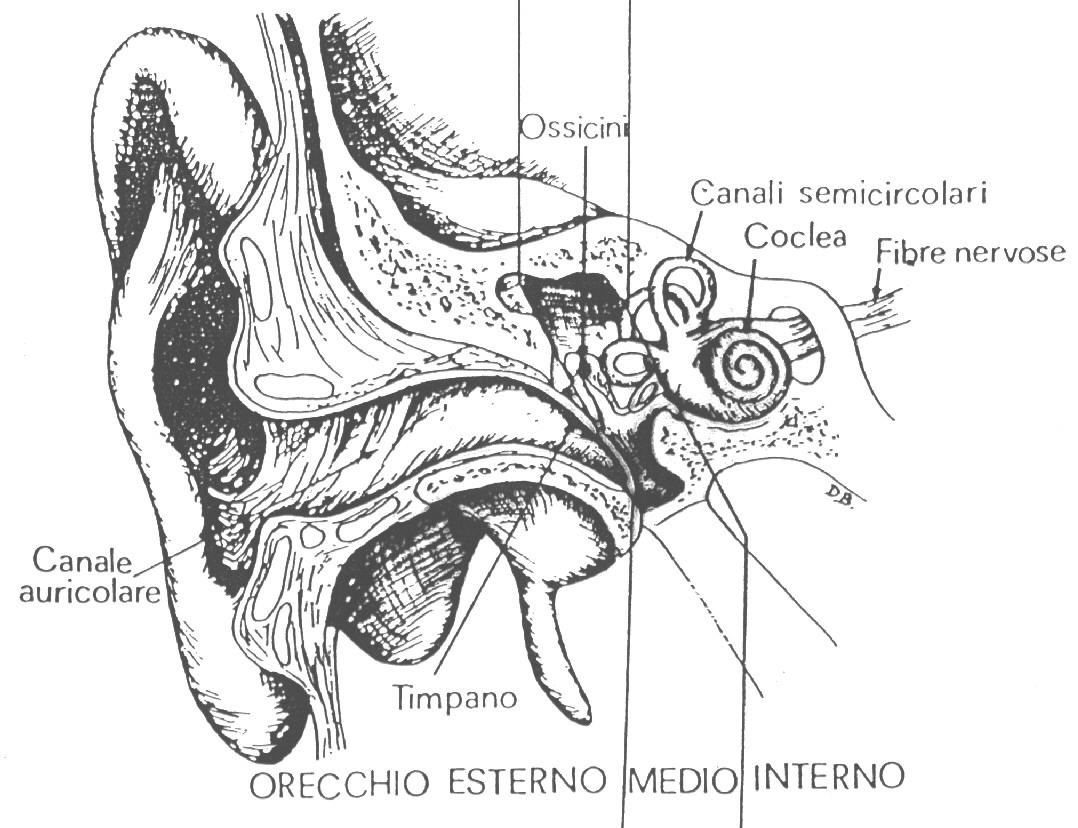
Il sistema uditivo umano può essere visto composto di tre parti: l’orecchio esterno (o padiglione auricolare), l’orecchio medio e l’orecchio interno. All’interno del padiglione auricolare è presente un condotto chiamato canale auricolare (o condotto uditivo) il quale termina su una membrana chiamata timpano. La membrana timpanica è un diaframma sottile, elastico, molto resistente, impermeabile all’acqua e all’aria che separa l’orecchio esterno dall’orecchio medio.
Figura 1: Orecchio umano
L’orecchio medio è costituito da una cavità interna dell’osso del cranio, contenente anch’essa aria, e da una complessa catena di ossicini atti a trasmettere la vibrazione della membrana timpanica all’organo dell’udito propriamente detto, la coclea, che si trova nell’orecchio interno. Sempre nell’orecchio interno si trova un secondo organo che non ha niente a che vedere con il sistema uditivo: il labirinto (o canali semicircolari). Esso è sede del centro dell’equilibrio, e noi non lo analizzeremo.
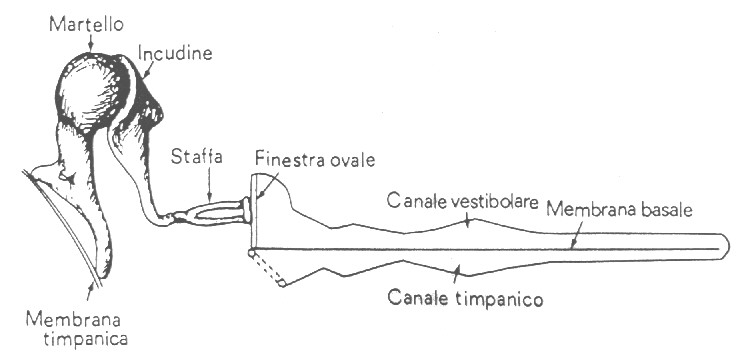
Figura 2: Ossicini e rappresentazione srotolata della coclea
Gli ossicini che si trovano dentro l’orecchio medio sono visibili ingranditi in figura 2: martello, incudine e staffa sono incernierati fra loro. Il primo è a contatto con la membrana timpanica, il terzo invece poggia su un ulteriore diaframma con caratteristiche simili a quelle del timpano, la finestra ovale, che lo collega alla coclea. All’interno della coclea però non si trova aria, ma un liquido con impedenza simile a quella dell’acqua, e quindi mille volte superiore a quella dell’aria.
Ora, la membrana timpanica ha un’impedenza solo di poco superiore a quella atmosferica e questa è compensata dalla forma del canale auricolare dell’orecchio esterno che effettua un caricamento a tromba per permettere un perfetto accoppiamento di impedenza tra il condotto e il timpano. Il risultato è un ottimo trasduttore del campo acustico che effettua il massimo trasferimento di energia. Bisogna però notare che il condotto è piccolo perciò funziona meglio a frequenze alte (3-5000 Hz), mentre a basse frequenze l’impedenza è disadattata e la risposta è minore (vedremo comunque che questo non è un problema).
Il trasferimento di energia dalla membrana timpanica alla finestra ovale è invece più problematico, in quanto il liquido che si trova all’interno della coclea ha, come già detto, un’impedenza mille volte superiore a quella dell’aria e inoltre al suo interno il suono viaggia ad una velocità 4-5 volte superiore: il risultato è che l’impedenza della membrana timpanica è circa tremila volte inferiore a quella della finestra ovale e quindi, se fossero messe a contatto diretto, il trasferimento d’energia sarebbe scarsissimo.
Gli ossicini funzionano quindi come delle leve, trasformando cioè i grandi movimenti associati a piccole forze della membrana timpanica nei piccoli movimenti e grandi forze della staffa. Un meccanismo di questo tipo è detto trasformatore meccanico d’impedenza, e benché aumenti il rapporto tra la pressione interna e la pressione sonora ricevuta dall’esterno non è un amplificatore vero e proprio perché questo processo è eseguito diminuendo la velocità dell’onda: in altre parole, si accresce un’energia a spese di un’altra.
Il segnale così trasformato giunge alla coclea (chiamata anche chiocciola per la sua forma) che in figura 2 è rappresentata "srotolata". La chiocciola è composta di due canali (o scale) lunghi 30mm posti a contatto fra loro attraverso la membrana basale: il canale vestibolare, che porta il suono verso il centro della chiocciola, e il canale timpanico, che guida il segnale nel percorso verso l’esterno.

Figura 3: Percorso seguito dal
segnale sonoro nella coclea
(in alto a sinistra è visibile il punto in cui poggia la
staffa)
La membrana basale è sottoposta ad uno sforzo mentre il suono la percorre, dovuto alle differenze di pressione che si vengono a creare nei due condotti posti a contatto, e questi sforzi sono registrati dalle cellule ciliate (vedi figura 4) che affidano il nuovo segnale a una rete neurale. Grazie ad essa il nostro cervello riceve un’informazione estremamente selettiva di come il suono sia distribuito alle varie frequenze. I tempi di risposta non sono istantanei, ma variano dai 25 ai 150 millisecondi a seconda della frequenza del segnale: si può dire che i suoni ad alta frequenza vengono uditi prima.
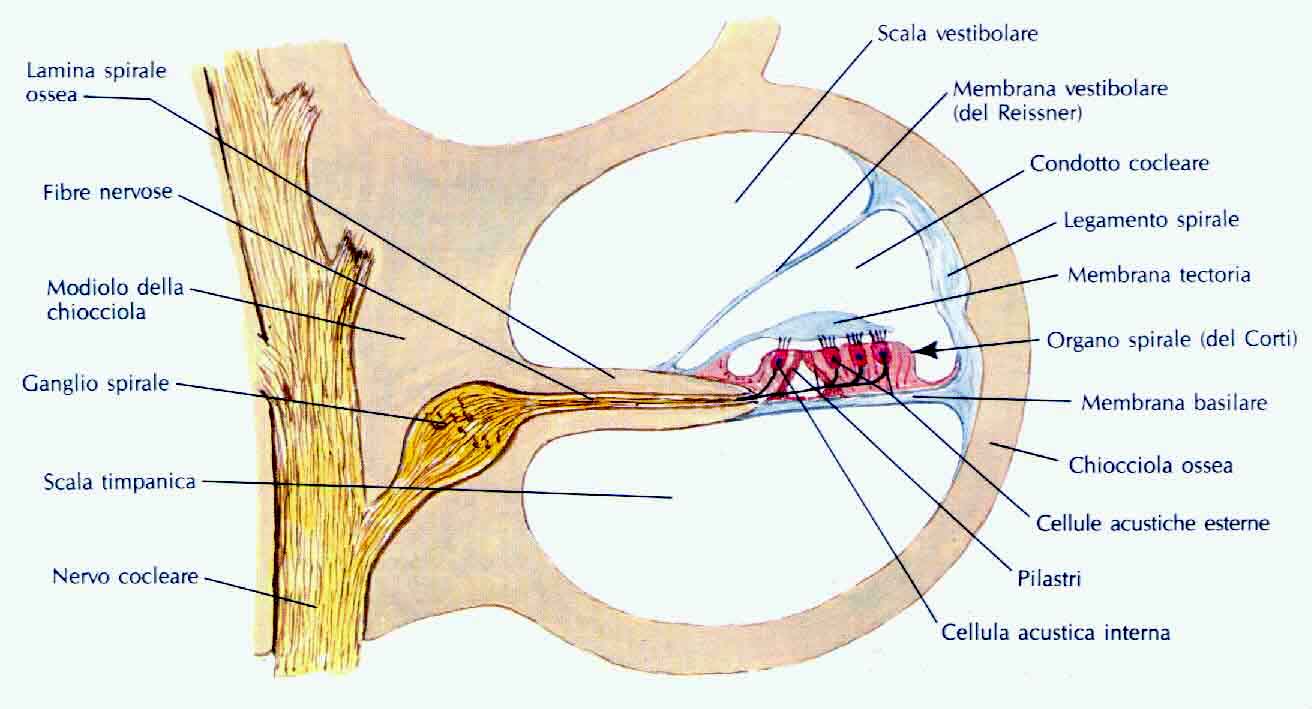
Figura 4: Sezione trasversale di un giro di chiocciola
Infatti all’ingresso della chiocciola la membrana basale è sottile e tesa come una corda di violino e l’impedenza del liquido all’interno della coclea è maggiore (in quanto il condotto è più largo): la frequenza di risonanza in questa zona è quindi alta. Procedendo verso il centro la membrana diventa più spessa e meno tesa, fino ad essere come una corda di contrabbasso: questo meccanismo fa sì che le componenti del suono a frequenze basse trovino la loro zona di risonanza solo dopo aver percorso i 30 mm di lunghezza del canale vestibolare. Perciò esse sono udite con un certo ritardo ed attenuate.
Essendo il canale di trasmissione unico, le componenti di suono a basso volume sono rese inudibili da quelle ad alto volume e frequenza prossima alla loro. Questo fenomeno è detto di "mascheramento", e viene sfruttato per compattare informazioni audio come nel caso dei minidisc e dei file MP3, nei quali vengono eliminati i contributi che il sistema uditivo non percepirebbe.
Sensazione sonora
Abbiamo quindi visto che la risposta del nostro sistema uditivo non è uguale a tutte le frequenze: possiamo dire che due suoni a frequenze diverse possono avere la stessa intensità ma dare un livello di sensazione diversa. Il diagramma 1 riportato du seguito è stato ottenuto sperimentalmente, e indica la soglia di udibilità, cioè la minima intensità che deve avere un suono per essere udito alle varie frequenze, e la soglia di dolore, oltre la quale il suono ha effetti dannosi anche per brevi esposizioni. Fra queste due linee si estende l’area dei suoni udibili dall’uomo.
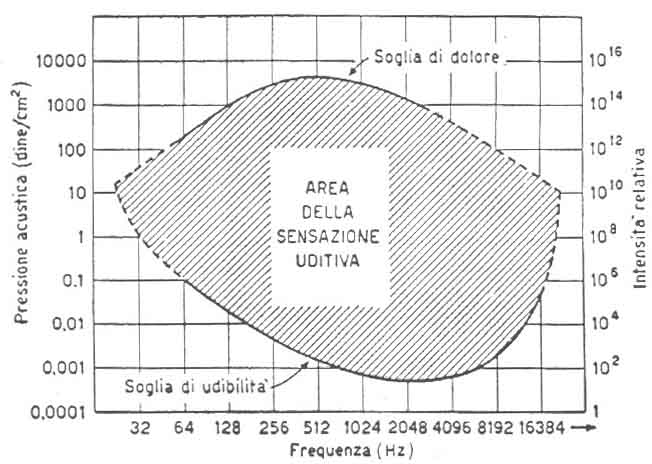
Diagramma 1: Area della sensazione uditiva
Un diagramma più significativo fu elaborato negli anni ’30 dai ricercatori Fletcher e Munson, che prendendo in esame un elevato numero di soggetti elaborarono le curve di isosensazione, o isofone, che rappresentano il livello in pressione sonora che deve avere un suono per dare la stessa sensazione alle varie frequenze. L’osservatore è sottoposto alternatamente ad un tono puro di una certa frequenza e ad un altro tono alla frequenza di riferimento (1000 Hz). Di quest’ultimo viene regolata l’intensità fino a dare la stessa sensazione del primo suono, e in questo modo si stabilisce a quale curva appartiene la prima coppia di valori (frequenza – intensità).
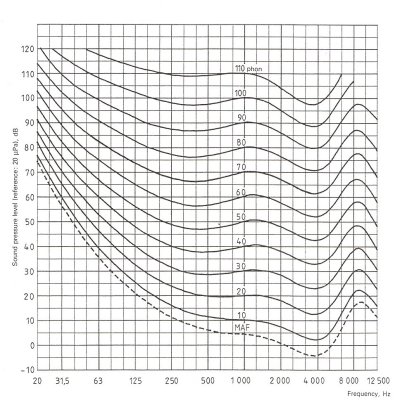
Diagramma 2: Fletcher Munson (ISO 226:1987, appendice A)
La curva inferiore, denominata MAF (Minimum Audible Field), riporta la soglia di udibilità binaurale in un campo frontale di toni puri per persone otologicamente normali di età compresa tra i 18 ed i 30 anni. A 1000 Hz la soglia vale 4,2 dB. (Fonte: sito internet prof. Massimo Garai, Università di Bologna)
Come vedremo più avanti, queste curve servono a valutare le misure che vengono effettuate con sistemi che hanno una risposta uguale a tutte le frequenze. Esse inoltre fanno parte del "Decreto misure" del marzo ’98: infatti la normativa italiana è molto avanzata riguardo ai sistemi di misurazione, in quanto si basa sulla risposta fisiologica dell'orecchio umano. Per comprendere appieno il diagramma di Fletcher Munson, vediamo ora la definizione del decibel.
La scala dB
Le curve isofoniche hanno tutte forma molto simile, con picco
di udibilità intorno ai 4000 Hz, ma si può notare come al
crescere dell’intensità la risposta del sistema uditivo si
appiattisce. Ciò nonostante è possibile ricavare l’unità
di raddoppio, ovvero il fattore per cui devo moltiplicare l’intensità
sonora per avere una sensazione di raddoppio. Tale valore fu
stabilito da Graham Bell in 3,16, ovvero![]() . Ribadiamo che esso
è solo un valore mediato, in quanto la risposta ad una
variazione di pressione sonora è diversa a seconda della
frequenza e dell’ampiezza.
. Ribadiamo che esso
è solo un valore mediato, in quanto la risposta ad una
variazione di pressione sonora è diversa a seconda della
frequenza e dell’ampiezza.
Prendendo una scala arbitraria, alle varie pressioni potremmo avere dei risultati come questi
| Pressione sonora | Sensazione (S) |
| 0,01 Pa | 1 |
| 0,0316 | 2 |
| 0,1 | 3 |
| 0,316 | 4 |
| 1 | 5 |
dove un aumento di S di un’unità equivale ad una sensazione di raddoppio. Bell definì la sensazione sonora come:
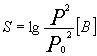
dove l’unità di misura tra parentesi quadre è il Bel,
mentre P0 è la pressione di riferimento,
stabilita in ![]() Pa,
corrispondente al suono più debole udibile dall’uomo a 1000
Hz. Da notare che ora non è più considerato tale, come mostra
la curva MAF, comunque continua ad essere preso come pressione di
riferimento. Occorre inoltre precisare che con l’espressione
"lg" intendiamo "logaritmo in base 10", così
come con "ln" intendiamo "logaritmo in base e".
Pa,
corrispondente al suono più debole udibile dall’uomo a 1000
Hz. Da notare che ora non è più considerato tale, come mostra
la curva MAF, comunque continua ad essere preso come pressione di
riferimento. Occorre inoltre precisare che con l’espressione
"lg" intendiamo "logaritmo in base 10", così
come con "ln" intendiamo "logaritmo in base e".
Questa scala si rivelò però essere troppo grossolana, ed oggi l’unita di misura più comunemente usata è il decibel (dB), ovvero il decimo di Bel. Per evitare confusioni il valore in dB è chiamato livello (L) e non sensazione, per cui scriveremo:
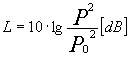
Alcune osservazioni: un suono a 0 dB, secondo Bell, corrispondeva al suono più debole udibile a 1000 Hz (infatti perché il logaritmo sia zero il suo argomento deve essere 1, ovvero P deve essere uguale a P0). Il fatto che i termini di pressione siano elevati al quadrato suggerisce che il nostro sistema uditivo abbia una risposta proporzionale al loro valor medio efficace, e quindi al contenuto energetico (che sappiamo essere proporzionale al quadrato della pressione).
In definitiva le caratteristiche con cui posso costruire uno strumento più simile all'orecchio umano funziona a livelli di pressione RMS con costante di tempo fast (125 ms). In formula:
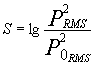
La scala dB(A)
Per raggiungere una buona approssimazione della risposta umana occorre inoltre compensare strumentalmente il fatto che l'orecchio sente meglio le frequenze alte rispetto alle basse. Questa operazione, detta di ponderazione, è eseguita tramite il diagramma di Fletcher Munson, andando cioè a vedere a quale curva isofonica appartiene una determinata coppia frequenza-livello. Per facilitare l'operazione è sufficiente avere a disposizione un grafico di Fletcher Munson ribaltato, che ci permette di stabilire quale valore dobbiamo sommare ai livelli sonori ottenuti alle varie frequenze per ottenere l'effettiva sensazione umana.
Come già detto, le curve isofoniche sono simili tra loro, ma comunque variano all'aumentare del livello, per cui avremmo bisogno di più curve da utilizzare nei vari casi. A tale riguardo esistono la curva A (per livelli sotto i 60 dB), la curva B (tra 60 e 80 dB), la curva C (oltre 80) e la curva D (per rumori molto forti, come quelli degli aerei) e si definiscono le misure in dB(A), dB(C) ecc. a seconda della curva di ponderazione utilizzata. Per evitare confusioni le misure prive di ponderazione possono essere indicate in dB(Lin).
Ciò nonostante, per i nostri scopi sarà utile avere a disposizione la sola curva di ponderazione A, di cui sono riportati anche i valori tabellati. Infatti la curva B e la curva D non sono prese in considerazione dalla legge, mentre la C riguarda solo i rumori molto forti.
Per quale motivo utilizziamo solo la curva A
(Fonte: sito internet prof. Massimo Garai, Università di Bologna)
La curva di ponderazione "A" è risultata quella in media meglio correlata con la risposta soggettiva umana a rumori generici a larga banda; questo fatto, unito alla facilità di una misurazione fonometrica in dB(A), ha portato all'adozione della curva "A" in molte norme e leggi nazionali ed internazionali. D'altra parte, è ben noto che questo modo di procedere si presta a molte critiche:
- le curve isofoniche sono state costruite lavorando con toni puri, mentre la curva "A" viene in genere usata per valutare rumori a larga banda;
- peraltro, è ormai ampiamente dimostrato che la curva "A" non da una valutazione adeguata quando il rumore abbia forti componenti tonali o sia di tipo impulsivo;
- il disturbo da rumore a bassa frequenza è certamente sottostimato utilizzando un singolo numero in dB(A).
Per questi ed altri motivi si ritiene oggi che la curva "A" non abbia più quel significato che originariamente le si voleva attribuire. Ciononostante, la curva "A" resta per la sua semplicità un riferimento comune per una prima approssimata valutazione dei rumori a larga banda. In realtà, la motivazione più forte al mantenimento della curva "A" sembra essere la sua onnipresenza nelle normative di settore. A questo punto il suo significato è puramente convenzionale, ragion per cui nelle normative di elettroacustica ,che definiscono le caratteristiche dei misuratori di livello sonoro, si rifugge dal riferimento a pretese e ormai superate valenze psicoacustiche e si definisce la curva "A" come un filtro nel dominio della frequenza dato da una precisa espressione matematica.
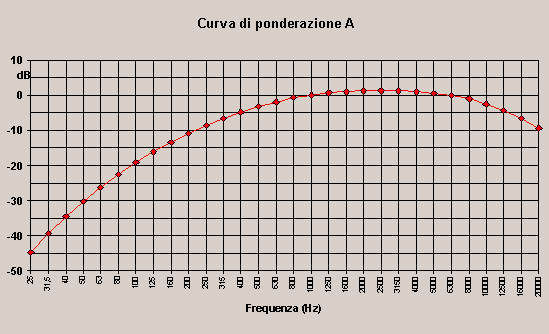
Tabella 1: Ponderazione A
Notare che per definizione il fattore di correzione a 1000 Hz è 0.
DANNI AL SISTEMA UDITIVO UMANO
Rumore impulsivo
Rumori istantanei ma con valore di picco molto forte possono causare danni irreversibili al sistema uditivo umano. Per questo motivo la normativa europea e quella italiana impongono dei limiti al massimo valore di picco tollerabile negli ambienti.
Da notare è che tale valore non può essere mediato nel tempo, neanche nei 125 ms, per cui il livello di riferimento preso è LMAX,PEAK (cioè il livello massimo ottenuto confrontando tutti i livelli istantanei). Secondo la normativa europea tale valore non deve essere maggiore ai 130 dB(C). La normativa italiana non ha ancora recepito la direttiva europea (anche se prima o poi dovrà farlo), e stabilisce questo limite in 140 dB(Lin).
L'inconveniente è chiaro nel caso di locali pressurizzati, che rischiano di finire fuori norma a causa di onde intense ma a frequenza bassissima (come quelle originate dalla chiusura di una porta), le quali effettivamente non provocano danni all'orecchio umano.
Esposizione breve a livelli alti
Esposizioni di poche ore a livelli alti possono causare, per via semplicemente della sollecitazione meccanica, un temporaneo malfunzionamento dell'organo dell'equilibrio. Questo, oltre a labirintite, nausea, perdita d'equilibrio, causa anche problemi di guida dei veicoli: per cui dopo una serata in discoteca è possibile avere difficoltà nel condurre un automezzo pur non avendo bevuto alcolici.
Esposizione prolungata a livelli medio alti
Esposizioni di diverse ore ogni giorno a livelli medio alti negli anni causa danni permanenti al sistema uditivo umano.
Le diagnosi sono effettuate in cabine d'ascolto, dove al paziente vengono fatti ascoltare toni puri a varie frequenze, partendo dal valore minimo udibile e salendo di volume fino a quando il suono è effettivamente udito dal paziente: questo permette di stabilire qual è stata la perdita di sensibilità alle varie frequenze, e di tracciare degli audiogrammi. Ovviamente la misura dei livelli sonori è effettuata in dB(A).
Vediamo ora qualche risultato ottenuto sperimentalmente su diversi soggetti.
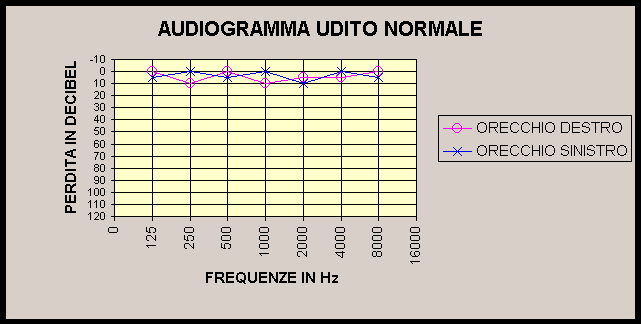
Il risultato dell'esame audiometrico riportato qui sopra illustra un udito pressoché normale. I rilevamenti alle varie frequenze sono infatti in prossimità dello 0 dB.
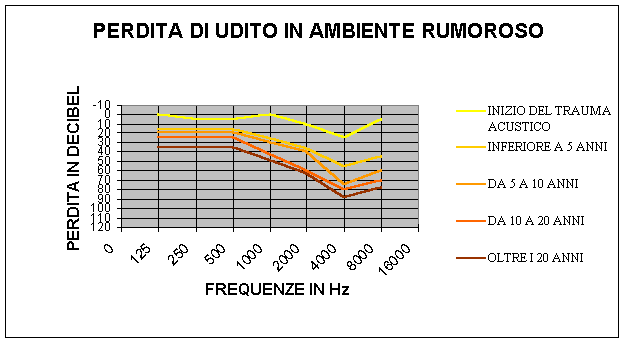
Esaminando i danni causati da un'esposizione prolungata ad un livello sonoro di 90 dB, si nota come la perdita di udito sia più grave in corrispondenza dei 4000 Hz. Questo deriva dal fatto che la chiocciola a tali frequenze è più sensibile e quindi più esposta ai danni. La ragione per cui il sistema uditivo umano si è sviluppato fino ad essere più sensibile alle frequenze intorno ai 2000/4000 Hz è che il più alto contenuto informativo della voce umana, ovvero le consonanti, si situa proprio a quelle frequenze. Perciò una persona audiolesa (e in Italia lo è il 5% della popolazione) sente meglio le vocali (che sono a 400 Hz ca. ed hanno un'intensità maggiore) rispetto alle consonanti, per cui il più delle volte capisce che le si sta parlando, ma non comprende ciò che le viene detto.
Una soluzione al problema viene dalle protesi. Esse però non possono funzionare come un amplificatore hi-fi, in quanto amplificando in modo lineare a tutte le frequenze causerebbero ulteriori danni al malato. Una protesi deve essere in grado di amplificare maggiormente le frequenze ove la perdita è più grave. Deve inoltre ridurre il guadagno quando il suono in ingresso è già ad alto livello. La risposta tecnologica attualmente in fase di evoluzione è il controllo di guadagno a microprocessore.
ASPETTI INGEGNERISTICI
Somma di segnali
Somma coerente
Prendiamo il caso di un tubo in cui poniamo alle estremità due altoparlanti e al centro un microfono collegato ad un trasduttore di segnale. Mettendo in funzione il primo altoparlante otteniamo dal trasduttore una certa forma d'onda (intensità in funzione del tempo). Accendendo il solo secondo altoparlante otteniamo un'onda uguale alla prima. Nei due casi ottengo i seguenti livelli:
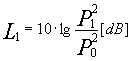
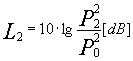
Se li metto in funzione contemporaneamente, facendo loro trasmettere lo stesso segnale perfettamente in fase, istante per istante le due pressioni sonore si sommano.
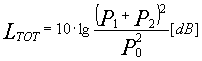
Se P1=P2
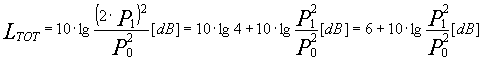
Per cui giungiamo al sorprendente risultato che ![]()
oppure che![]() !!!
!!!
Se sommo 2 livelli non uguali devo invece fare riferimento alla prima formula del livello totale.
Somma incoerente
L'esempio che abbiamo visto non è però realistico, in quanto non posso ricevere due suoni assolutamente identici: a parte che solitamente i due suoni sono già diversi in partenza, comunque essi percorrono distanze diverse prima di giungere al microfono, per cui hanno fase tra di loro random: a volte si sommano raddoppiando effettivamente la pressione sonora, a volte s'annullano, a volte sono a fase intermedie.
Pertanto per calcolare il livello sonoro totale occorre fare un'ipotesi diversa, vale a dire sfruttando il principio di conservazione dell'energia: la densità d'energia sonora sarà uguale alla somma aritmetica delle due prese singolarmente.
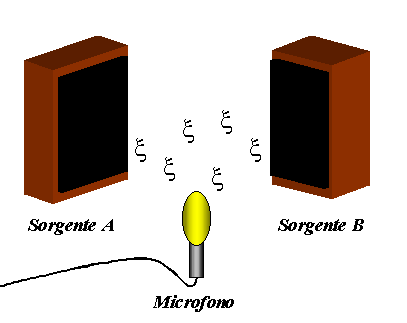
Figura 5: Somma incoerente
![]() è normalmente
proporzionale all'energia, perciò si può supporre
è normalmente
proporzionale all'energia, perciò si può supporre![]() e quindi:
e quindi:
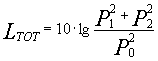
Se P1=P2
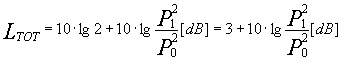
Per cui ad esempio ![]() , oppure
, oppure ![]() . In linea di massima, per somma di due livelli
intendiamo sempre somma incoerente.
. In linea di massima, per somma di due livelli
intendiamo sempre somma incoerente.
Nel grafico qui sotto è indicato quanto dobbiamo sommare al livello del maggiore dei due segnali per ottenere il livello totale.
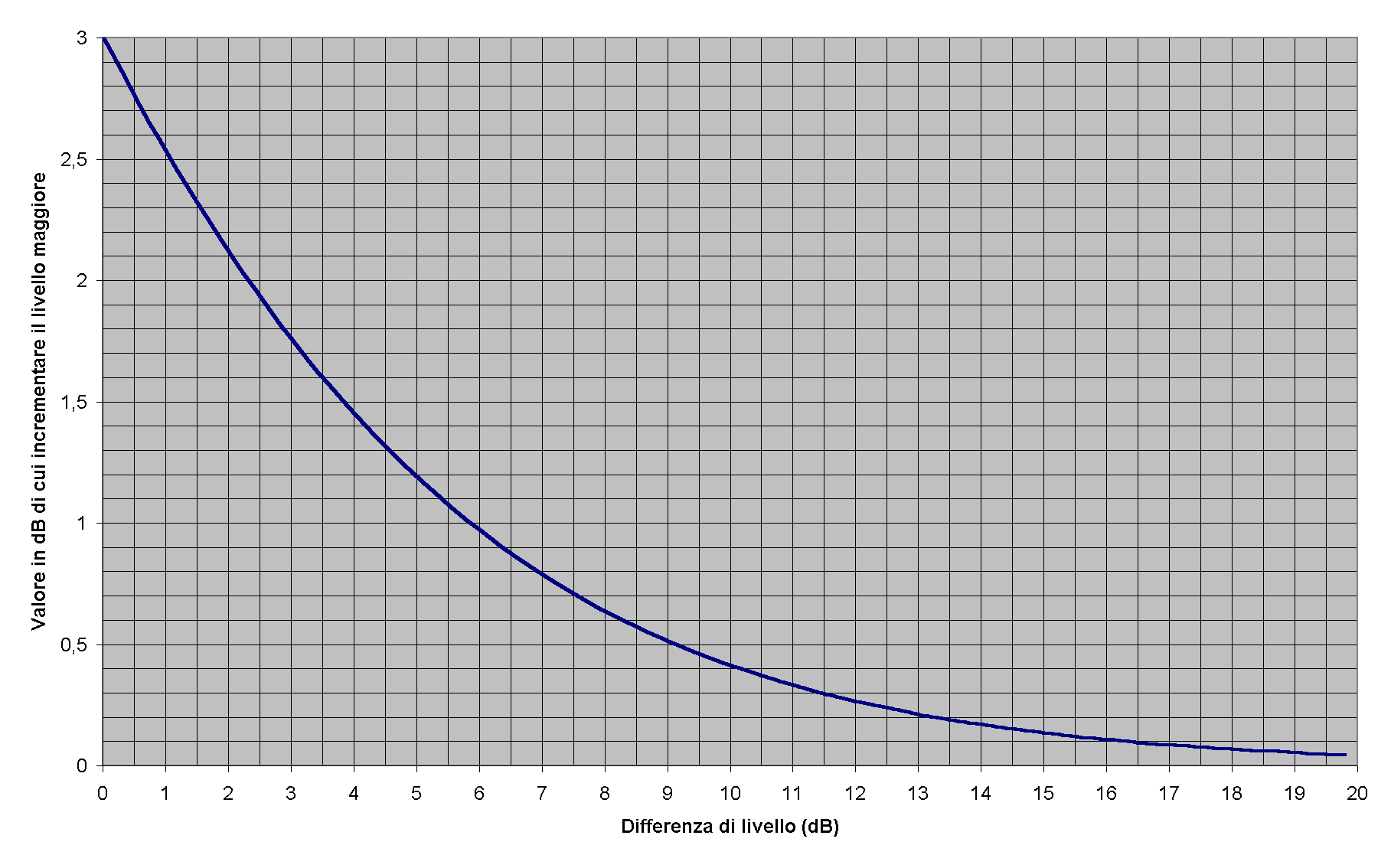
Infatti, grazie alle proprietà del logaritmo il valore da
sommare dipende solo dalla differenza di livello tra i due
segnali e non dal livello di partenza. Come si può notare, se
viene sommato un livello inferiore di 10 dB rispetto al primo,
questo rimane sostanzialmente invariato (+0,4) per cui
solitamente si dice che ![]() .
.
L'effetto pratico è che un fonografo non avverte nessuna differenza all'attivazione della sorgente più debole, quando invece il nostro orecchio se ne accorge: il suono è cioè trascurabile dal punto di vista del livello totale, ma è comunque udibile (sempre se non siamo in presenza del fenomeno di mascheramento).
Se dall'espressione di L1 e L2 ricavo ![]() e
e ![]()
![]() e
e
![]()
Sostituendo nell'espressione di LTOT ottengo
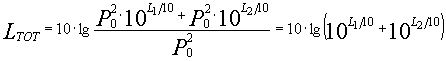
Esercizio
Di un segnale sonoro mi vengono forniti i livelli delle componenti alle varie frequenze, ovvero mi viene dato lo spettro (questo concetto verrà meglio approfondito nelle prossime lezioni). I dati sono riportati nella tabella sottostante:
Frequenza |
Livello in dB |
Fattore di correzione |
Livello in dB(A) |
63 |
70 |
-26,2 |
43,8 |
125 |
80 |
-16,1 |
63,9 |
250 |
76 |
-8,6 |
67,4 |
500 |
68 |
-3,2 |
64,8 |
1000 |
63 |
0 |
63 |
2000 |
78 |
1,2 |
79,2 |
Mi viene richiesto il livello totale in dB
![]()
Proviamo ora a calcolare il livello totale in dB(A): come si vede dalla tabella, è sufficiente applicare i fattori correttivi indicati precedentemente per ottenere i livelli in dB(A)
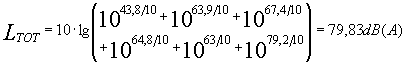
Occorre osservare che la seconda cifra decimale non ha alcun significato fisico in quanto la sensibilità dell'orecchio umano e di molti strumenti non arriva neanche al decimo di decibel.
Confrontando graficamente (con i tipici istogrammi) i valori in dB e in dB(A), mi accorgo che quello che a 125 Hz sembrava essere un picco, in verità è sovrastato dalla componente a 2000 Hz che è molto più udibile di essa.
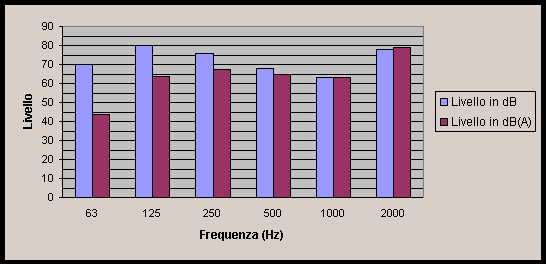
Come si può vedere, tutte le componenti risultano essere trascurabili dal punto di vista del livello rispetto a quella a 2000 Hz.