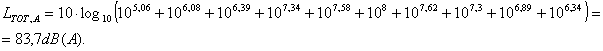ACUSTICA
PSICOFISICA
L�apparato uditivo umano � in grado di percepire un
range di pressione sonora compreso tra 20 mPa e 60 Pa (per pressioni superiori possono
insorgere danni uditivi immediati); la capacit� dinamica del nostro udito si
estende cio� per oltre 6 ordini di grandezza. E� stato inoltre provato che la
risposta soggettiva ad uno stimolo, sia esso uditivo, olfattivo o comunque
relativo ai nostri 5 sensi, risulta correlata alla sua energia e quindi al
quadrato della pressione (infatti la densit� di energia � data da ![]() , dove
, dove ![]() �� il valore efficace
della pressione sonora e
�� il valore efficace
della pressione sonora e ![]() � l�ampiezza della pressione) ancor pi� che alla pressione
stessa, quindi il campo di variazione diventa dell� ordine di 1012.
� l�ampiezza della pressione) ancor pi� che alla pressione
stessa, quindi il campo di variazione diventa dell� ordine di 1012.
Per questo comportamento non lineare dell�udito e
per evitare di lavorare con valori di pressione, intensit�, potenza, densit� di
energia e velocit� (queste sono le grandezze fondamentali per lo studio di un
onda sonora) molto grandi o molto piccoli dispersi su un campo troppo esteso,
si � deciso di adottare una scala compressa, di tipo logaritmico. Una scala di
questo tipo permette il confronto tra i valori in esame di una determinata
grandezza con dei valori standard di riferimento della stessa grandezza. Si �
cos� introdotto il decibel (dB) per misurare, ad esempio, il livello di
pressione sonora:
![]() ,�
,� ![]() �mPa � la pressione di
riferimento.
�mPa � la pressione di
riferimento.
E� evidente che il decibel definisca una quantit� adimensionale,
ciononostante nella pratica � adoperato come una vera e propria unit� di
misura.
Per meglio capire perch� la risposta dell�apparato
uditivo agli stimoli sia non lineare si fa riferimento alla sensazione sonora e
all�anatomia dell�udito stesso.
Sensazione sonora (S)
Quando si parla di sensazione sonora, in inglese
loudness, ci si riferisce alla caratteristica di un suono che lo fa giudicare
pi� o meno intenso da un ascoltatore.
Per misurare tale sensazione si � introdotto il concetto di livello di
sensazione sonora, ottenuto variando il livello di intensit� di un suono
rispetto ad un altro di riferimento e si sono determinate delle curve dette
isofoniche che rappresentano un ugual livello di sensazione.
�Fletcher e
Munson nel 1937 ottennero la prima famiglia di curve isofoniche, per ascolto
binaurale in cuffia , presentando a soggetti otologicamente normali un suono
puro, alternato ad un suono di riferimento alla frequenza di 1 kHz con livello
di pressione sonora variabile. Il livello di pressione sonora del suono di
riferimento, per cui la sensazione sonora � uguale a quella del suono puro in
esame, fu definito come livello di sensazione sonora espresso in phon. F. e M.
confrontarono le sensazioni prodotte per una serie di suoni puri di diversa
frequenza e intensit�, ottennero una famiglia di curve, ciascuna delle quali �
caratterizzata da un valore in phon, numericamente uguale al livello di
pressione sonora del tono di frequenza 1 kHz, che causa la stessa sensazione.
�
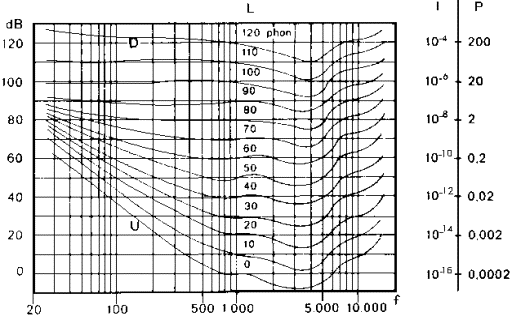
Figura 1: Curve isofoniche di Fletcher e Munson.
Il livello di sensazione sonora � per� una grandezza
soggettiva, in quanto legata alla sensibilit� uditiva dell�individuo, relativa,
essendo ottenuto dal confronto con un tono puro a 1 kHz e fortemente
influenzata dalle condizioni di ascolto (ad esempio potrei fare le misurazioni
con suoni presentati in cuffia, con ascolto monoaurale o binaurale, o potrei
usare un altoparlante, in campo libero o diffuso).
Un miglioramento delle misurazioni di F. e M. fu
eseguito da Robinson e Dadson nel 1956 che scoprirono le curve isofoniche
adottate dalla normativa attuale (ISO 226).
Figura 2: Curve isofoniche riportate nella norma ISO 226.
Essi utilizzarono suoni puri riprodotti direttamente
da un altoparlante, in campo libero. Con questo termine si intende che il suono
generato da una sorgente si propaga in un mezzo illimitato, privo di
discontinuit� od ostacoli. Ovviamente condizioni del genere sono solo una
idealizzazione delle reali condizioni in cui un suono si propaga. Tuttavia se
siamo in uno spazio all�aperto, con condizioni atmosferiche stabili e omogenee,
e in cui non vi siano superfici od ostacoli in una zona sufficientemente ampia
attorno alla sorgente, possiamo approssimare la situazione con quella di campo
libero. Oppure, a livello di laboratorio, se operiamo nella cosiddetta camera
anecoica, in cui tutte le superfici assorbono completamente le onde sonore che
le investono e l�unico suono esistente all�interno � quello prodotto dalla
sorgente per assenza di suono riflesso dalle superfici.
�Rispetto
all�audiogramma normale di F. e M. le differenze si hanno soprattutto nei campi
di frequenza prossimi a 4 kHz e 8 kHz, questo perch� R. e D. lavorarono in
assenza di un ascoltatore e quindi non ebbero problemi di diffrazione dell�onda
sonora intorno alla testa e al padiglione auricolare. In entrambe le famiglie
di curve si nota una zona di scarsa sensibilit� sonora in corrispondenza delle
basse frequenze, mentre intorno ai 3-4 kHz si ha una zona di massima
sensibilit�. Ci� significa che a basse frequenze la sensazione sonora aumenta
rapidamente all�aumentare del livello di pressione sonora; ad alti valori di
frequenza le isofoniche sono quasi parallele e la sensazione aumenta meno
rapidamente, il che � un indicatore di non linearit�. Una novit� introdotta da
R. e D. � la curva isofonica a 4,2 phon, indicata con MAF (Minimum Audible
Field), rappresenta, per ogni frequenza, il minimo livello di pressione sonora
per cui un suono � udibile, e corrisponde alla soglia uditiva. La norma ISO 226
� attualmente in fase di revisione e molto probabilmente nella nuova versione
riporter� curve isofoniche leggermente diverse, sulla base di studi condotti
negli anni ottanta e novanta in numerosi laboratori.
A livello teorico attraverso le curve isofoniche
sarebbe possibile stabilire per qualsiasi suono di frequenza diversa da 1
kHz� la corrispondenza tra sensazione
sonora (phon) e livello di pressione�
sonora (dB), ma in realt� per suoni di tipo complesso servirebbe una
valutazione diretta della sensazione. Servirebbe cio� conoscere la relazione
sensazione � livello di pressione di un suono a 1 kHz. Per la norma ISO 131, la
relazione fra sensazione s (in son) e livello di sensazione (in phon) era
espressa dalla relazione:
![]() ,
,
ossia:
![]() .
.
Per definizione il son � la sensazione prodotta da
un suono puro di frequenza 1 kHz e Lp= 40 dB. Anche se la ISO 131
non � pi� in vigore la definizione del son � data sempre da quella norma.
Poich� P e per definizione pari alla Lp di un suono puro a 1 kHz,
che produce nel soggetto la stessa sensazione del suono in esame (cio� per
frequenza di 1 kHz, ![]() �phon), si ricava che
per il suono puro a 1 kHz:
�phon), si ricava che
per il suono puro a 1 kHz:
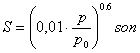 �.
�.
Questa relazione � confermata da numerose prove
sperimentali e stabilisce che la dipendenza della S da p � esponenziale, e
quindi la relazione tra livelli di sensazione sonora e livelli di pressione �
lineare. Per un aumento di 10 dB del livello si ha un raddoppio di sensazione.
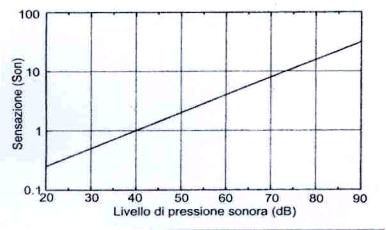
Figura 3: Relazione fra sensazione sonora e livello di pressione sonora per un suono di frequenza 1 kHZ.
Cenni all�anatomia e al funzionamento del sistema
uditivo
In natura ci sono mammiferi come i cani, che sono in grado di captare
suoni con frequenze comprese tra 15 e 40.000 Hz, i pipistrelli, tra 1.000 e
120.000; i delfini e le orche sono quelli con sensibilit� acustica pi�
sviluppata e percepiscono ultrasuoni fino a una frequenza di 200.000 periodi.
L�uomo invece � limitato all� intervallo di frequenze 16�20.000 Hz e nel
grafico seguente sono rappresentate, su base sperimentale, alle varie frequenze
la soglia di udibilit� (intensit� minima di un suono per essere udito) e quella
di dolore (intensit� minima per avere danni uditivi anche per brevi
esposizioni).��
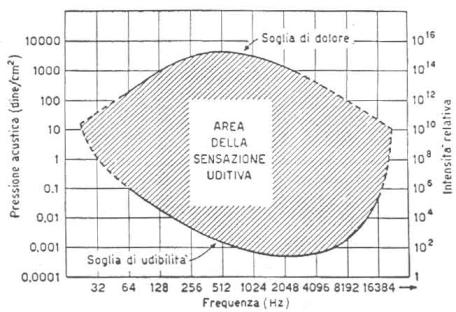
Figura 4: Area della sensazione uditiva.
In anatomia l�apparato uditivo umano si suddivide in:
a) orecchio esterno;
b) orecchio medio;
c) orecchio interno.
a) L�orecchio esterno � costituito dal padiglione auricolare e dal condotto uditivo esterno. Il padiglione auricolare ha una struttura cartilaginea ricoperta di cute ed ha la funzione di convogliare i suoni verso il condotto uditivo esterno; nell�uomo questa funzione � trascurabile dato che il padiglione ha perso l�originaria mobilit�. Il condotto uditivo esterno ha la lunghezza di 2,5 cm nell�adulto, nel suo decorso trasversale presenta 2 curvature e si chiude con la membrana timpanica. Il condotto uditivo svolge una funzione protettiva, sia meccanica sia termica, nei riguardi della membrana timpanica e attraverso il cerume si mantiene pulito. La funzione pi� importante del condotto � quella di convogliare l�energia sonora sulla membrana timpanica e di amplificare i suoni, comportandosi come un risonatore con frequenza di risonanza tra 3e 4 kHz.
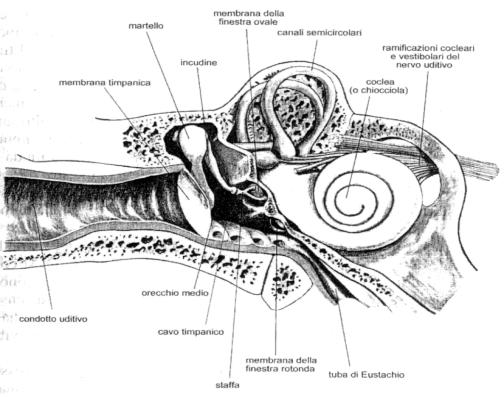
Figura 5: Schema anatomico dell�orecchio medio e della coclea.
b) L�orecchio medio � costituito da: cassa timpanica, tromba d�Eustachio e cellule mastoidee. La cassa timpanica � una piccola cavit� a forma di lente biconcava, ripiena d�aria; in essa ci sono 3 piccole formazioni ossee che costituiscono la catena degli ossicini: il martello, l�incudine e la staffa. La membrana timpanica, che separa la cassa timpanica dal condotto uditivo esterno, da un punto di vista fisico � molto sofisticata, in quanto la disposizione delle fibre al suo interno le consente di comportarsi come una membrana aperiodica (infatti � in grado di vibrare ugualmente in uno spettro molto ampio di frequenza) e smorzata (cio� si arresta immediatamente allorch� cessa la stimolazione vibratoria). La membrana timpanica, saldata al manico del martello, insieme con la catena degli ossicini e al legamento anulare della staffa, si comporta come un�unica struttura vibrante, le cui caratteristiche meccaniche possono essere in parte modificate dalla contrazione di due piccoli muscoli striati: il tensore del timpano e lo stapedio. Le cellule mastoidee sono costituite da una serie di cavit� ossee ma hanno scarsa importanza per l�udito. La tromba d�Eustachio � un sottile condotto, circa 4 cm lungo, che fa comunicare la cassa timpanica con l�ambiente esterno; la sua funzione principale � quella di equalizzare la pressione che si genera sulla faccia interna della membrana timpanica con quella che si realizza sulla faccia esterna, consentendo il passaggio dell�aria dall�esterno all�interno della cassa timpanica. Se tale passaggio � inibito all�interno della cassa si crea una modica depressione che altera in maniera sensibile le capacit� vibratorie del timpano. Da un punto di vista funzionale, l�orecchio medio funziona da adattatore di impedenza, trasmette cio� le vibrazioni dall�aria ai liquidi cocleari, senza perdita di energia nella trasmissione. Il sistema uditivo � in grado di variare l�impedenza dell�orecchio medio principalmente attraverso la contrazione del muscolo stapedio, che fa irrigidire la catena degli ossicini. Il riflesso stapeidale � attivato da un stimolo indicativamente superiore agli 85 dB ed � crociato, nel senso che uno stimolo all�orecchio destro provoca una reazione anche nel sinistro. Tale riflesso non svolge propriamente una funzione protettiva, come si sarebbe portati a pensare, perch� la riduzione di trasmissione dei suoni si ha per frequenze inferiori a 1kHz e in quanto il riflesso ha un tempo di reazione pari a 150 � 200 ms mentre il suono perviene alla coclea in 5 � 6 ms; esso allora serve a modificare le capacit� vibratorie per recepire meglio i suoni a basse frequenze. Una mancanza congenita o una distruzione delle strutture dell�orecchio medio portano non alla sordit� completa, ma bens� ad un deficit massimo di 60 dB.
c) L�orecchio interno � costituito da una serie di canali che sono in comunicazione tra di loro e che costituiscono il labirinto osseo. Asportando il labirinto osseo si trova un labirinto membranoso separato da quello osseo da un liquido chiamato perilinfa. All� interno del labirinto membranoso � presente l�endolinfa e il labirinto si distingue in posteriore (dove hanno sede le strutture deputate alla funzione dell�equilibrio) e anteriore o coclea (dove vengono svolte le funzioni uditive).
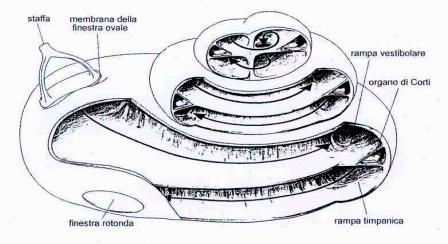
Figura 6:
Sezione trasversale della coclea.
�
La coclea � paragonabile ad un tubo attorcigliato su se stesso, lungo circa 35 mm, in cui si riconoscono 3,75 giri. Essa � divisa in tre parti da lamine membranose, una di queste � la membrana basilare su cui trova posto l�organo del Corti. Tale organo � costituito da cellule di sostegno e da cellule sensoriali, dotate di formazioni filamentose rigide: le cellule ciliate. Quando la staffa, sollecitata dalla catena degli ossicini, impone all�endolinfa un movimento ondoso, l�onda si propaga dalla base all�apice della coclea e quindi anche all�organo del Corti; allora una flessione delle cellule ciliate� crea un potenziale elettrico che stimola il nervo acustico. E� la teoria detta dell�onda migrante per la quale, si afferma che, se la coclea � stimolata da suoni ad alta frequenza, la massima escursione di vibrazione si ottiene a livello di giro basale, mentre i suoni a bassa frequenza riguardano l�apice.
L�apparato uditivo � pi� sensibile a suoni ad alta frequenza perch� la sensibilit� in ambito frequenziale varia in funzione della distanza lungo la membrana basilare e per suoni bassi in frequenza la massima risposta � in prossimit� dell�apice della coclea, dove l�orecchio � meno sensibile.
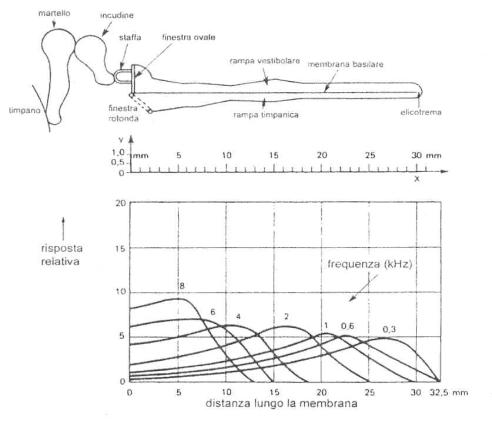
Figura 7:
Sezione longitudinale della coclea con corrispondente posizione del massimo
della risposta.
Il progresso tecnologico ha permesso di costruire apparecchiature capaci di analizzare fenomeni acustici di energia estremamente bassa; si � introdotto un microfono nel condotto uditivo e si � scoperto che l�orecchio emette suoni detti emissioni oto-acustiche. Queste sono di tre tipi:
I. Eco acustico: dopo che si � inviato un segnale nel condotto, tempo di risposta 10-20 ms si rileva un eco; poich� tale eco non � stato rilevato su animali morti, non si tratta solo di un fenomeno di riflessione;
II.
Prodotto di distorsione acustica: se si inviano due toni con
frequenze molto vicine f1 e f2 �si registra nel condotto un tono di frequenza ![]() ;
;
III. Emissione spontanea: nel condotto uditivo di alcuni soggetti normali si rilevano dei toni puri anche in assenza di stimolazione, il che � in linea con il modo di funzionare dell�orecchio: un trasduttore instabile di segnali acustici, capace di trasportare segnali sia dall�esterno verso l�interno che viceversa.
Curve di ponderazione
Quando si � parlato delle curve di Fletcher e Munson si � accennato al fatto che le misurazioni furono ottenute usando solo toni puri (mentre nella realt� quasi mai ci confrontiamo con suoni descritti da sinusoidi perfette, ma il pi� delle volte i suoni non hanno proprio nulla di armonico) e trascurando le varie possibilit� di provenienza direzionale del suono (trattando solo il caso della diffusione frontale), si trattava in altre parole di un�analisi troppo semplicistica. Da un punto di vista pratico poi, era difficilissimo con l�elettronica analogica di cui si disponeva sino a pochi decenni fa, creare degli strumenti di misura capaci di implementare curve dall�andamento cos� complesso come le isofoniche. Si � allora introdotto negli strumenti di misurazione del suono un circuito elettrico analogico, costituito di soli elementi passivi, che implementa una certa curva che al variare della frequenza d� luogo ad una valutazione del livello sonoro che si avvicina alla valutazione non lineare compiuta dagli esseri umani.
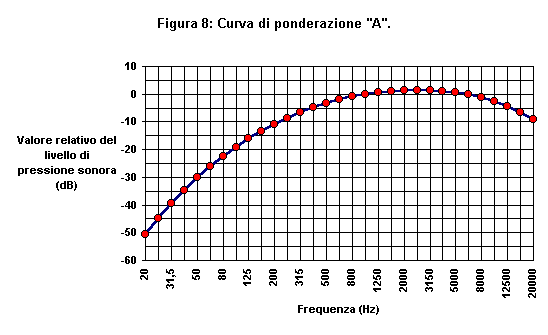
In particolare, prendendo alcune isofoniche e ribaltandole si possono ottenere dei filtri di ponderazione in frequenza fatti in modo che ad una soglia di sensazione pi� alta corrisponda una ponderazione pi� penalizzante. Ad esempio con la curva dei 40 phon si ottiene la curva �A� e ribaltando quelle a 70 e 100 phon si ottengono le ponderazioni �B� e �C�. Per alcune tipologie di rumore particolari sono state proposte delle apposite curve di ponderazione, ad esempio per il disturbo arrecato dal rumore aeronautico c�� la curva �D�. Un livello sonoro misurato con il filtro �A� viene espresso in dB(A) e cosi per gli altri filtri avremo i dB(B), i dB(C) ecc.
Per visualizzare altre curve
di ponderazione B, C, D fare clic col destro sulla figura e dal sottomen�
Oggetto Grafico scegliere Apri, poi ciccando 2 volte sulla riga di una delle
curve si disegnano/cancellano le stesse.
La curva �A� � risultata in media meglio correlata con la risposta soggettiva umana a rumori generici a larga banda, se a ci� si aggiunge la facilit� di una misurazione fonometrica in dB(A), si capisce il perch� questa curva sia stata adottata in molte norme e leggi a livello nazionale e internazionale.
Tabella 1: Valori
della curva �A� per le frequenze da 20 Hz a 20 kHz.
|
Frequenza (Hz) |
Ponderazione �A�
(dB) |
Frequenza (Hz) |
Ponderazione �A�
(dB) |
|
20 |
-50,5 |
800 |
-0,8 |
|
25 |
-44,7 |
1000 |
0,0 |
|
31,5 |
-39,4 |
1250 |
0,6 |
|
40 |
-34,6 |
1600 |
1 |
|
50 |
-30,2 |
2000 |
1,2 |
|
63 |
-26,2 |
2500 |
1,3 |
|
80 |
-22,5 |
3150 |
1,2 |
|
100 |
-19,1 |
4000 |
1,0 |
|
125 |
-16,1 |
5000 |
0,5 |
|
160 |
-13,4 |
6300 |
-0,1 |
|
200 |
-10,9 |
8000 |
-1,1 |
|
250 |
-8,6 |
10000 |
-2,5 |
|
315 |
-6,6 |
12500 |
-4,3 |
|
400 |
-4,8 |
16000 |
-6,6 |
|
500 |
-3,2 |
20000 |
-9,3 |
|
630 |
-1,9 |
|
|
E� necessario puntualizzare che dB e dB(A) sono grandezze tra loro
incommensurabili; se, cio�, devo fare la somma: ![]() la risposta non � univoca. Devo vedere la frequenza del suono
e in base ad essa trasformare i dB in dB(A) usando la curva di ponderazione.
Poi posso fare la somma e solo a 1 kHz ho:�
la risposta non � univoca. Devo vedere la frequenza del suono
e in base ad essa trasformare i dB in dB(A) usando la curva di ponderazione.
Poi posso fare la somma e solo a 1 kHz ho:�
![]()
Volendo fare un esempio pratico si consideri un motore da 3000
giri/min che equivalgono a 50 Hz e tale motore � costituito da 4 pale allora ho
una frequenza ![]() . Il livello sonoro � di 91 dB, mi chiedo: quanti dB(A) sono?
Dalla curva �A� vedo che a 200 Hz ho una ponderazione di �10,9 dB. Allora i
miei 91 dB corrispondono a circa 80,1 dB(A). Se voglio diminuire i dB(A) posso
intervenire sul motore utilizzando magari del materiale fonoassorbente, ma
posso anche considerarne un altro con caratteristiche diversi. Adopero un
motore da 3000 giri/min con 2 pale cio� ho una frequenza
. Il livello sonoro � di 91 dB, mi chiedo: quanti dB(A) sono?
Dalla curva �A� vedo che a 200 Hz ho una ponderazione di �10,9 dB. Allora i
miei 91 dB corrispondono a circa 80,1 dB(A). Se voglio diminuire i dB(A) posso
intervenire sul motore utilizzando magari del materiale fonoassorbente, ma
posso anche considerarne un altro con caratteristiche diversi. Adopero un
motore da 3000 giri/min con 2 pale cio� ho una frequenza ![]() .� La ponderazione
corrispondente a 100 Hz � di� -19,1 dB
per cui i miei 91 dB questa volte diventano 71,9 dB(A). Dal punto di vista
fisico il rumore non � cambiato, infatti l�energia � rimasta la stessa, ma il
lavoratore nel caso del motore con 2 pale sar� disturbato di meno: ci� che
conta sono i dB(A)!
.� La ponderazione
corrispondente a 100 Hz � di� -19,1 dB
per cui i miei 91 dB questa volte diventano 71,9 dB(A). Dal punto di vista
fisico il rumore non � cambiato, infatti l�energia � rimasta la stessa, ma il
lavoratore nel caso del motore con 2 pale sar� disturbato di meno: ci� che
conta sono i dB(A)!
Inquinamento acustico
Da un punto di vista fisico �rumore� e �suono� non sono definibili perch� troppi sono i fattori soggettivi che concorrono alla definizione dell�uno e dell�altro. Si pu� dire che il rumore � un suono non caratterizzato da una frequenza determinata o da vibrazioni regolari. Quindi qualsiasi cosa pu� emettere un rumore, il che rende difficile stabilire, per legge, limiti assoluti o fissare standard minimi a protezione della popolazione e dell�ambiente. L�inquinamento acustico pu� dipendere non solo da rumori, ma anche da suoni, da quelli che per qualcuno sono suoni e per qualcun altro sono rumori; per questo la legislazione si occupa di inquinamento acustico e non di rumore.
Per poter paragonare fra loro rumori di diversa intensit� e durata, si pu� calcolare il valore del rumore mediato in un determinato periodo di tempo: � il cosiddetto �livello continuo equivalente (Leq)�. Eventi sonori con un uguale valore di Leq, a parit� di tempo di misura, hanno lo stesso contenuto di energia sonora e quest�ultima pu� essere correlata ai possibili danni al sistema uditivo. La caratterizzazione oggettiva del disturbo da rumore tener conto dei seguenti parametri:
� Livello di rumore percepito istante per istante;
� Spettro delle frequenze componenti;
� Durata;
� Distribuzione nel tempo;
� Caratterizzazione acustica dell�ambiente in cui il rumore viene immesso (si tratta del cosiddetto �rumore di fondo�, che si riscontra in assenza della sorgente disturbante).
Tabella
2: Alcuni livelli sonori indicativi riferiti a sorgenti
|
SORGENTE
SONORA |
LIVELLO
SONORO IN dB(A) |
|
Soglia di udibilit� |
�������������������������������� 0 |
|
Soglia di rilevabilit� di un normale fonometro |
������������������������������� 20 |
|
Ambiente considerato molto silenzioso |
25 |
|
Conversazione sussurrata |
30 |
|
Frigorifero |
35 |
|
Condizionatore d�aria autonomo |
50 |
|
Auto a bassa velocit� |
55 |
|
Lavabiancheria lavaggio |
60 |
|
Conversazione normale |
60 |
|
Aspirapolvere |
70 |
|
Cacciata di W.C. |
70 |
|
Automobile |
71 |
|
Lavabiancheria centrifuga |
75 |
|
Traffico intenso |
75 |
|
Pianoforte |
80 |
|
Autocarro |
80 |
|
Treno in transito |
85 |
|
Strumento musicale a corda |
90 |
|
Clacson d�auto |
97 |
|
Strumento musicale a fiato |
100 |
|
Aereo in fase di decollo |
120 |
|
Soglia del dolore |
130 |
Il rumore pu� incidere profondamente sullo stato di benessere e quindi di salute dell�individuo. La scienza medica � concorde nell�affermare che gli eccessi di rumore oltre a danneggiare l�apparato uditivo, possono provocare disturbi al sistema nervoso, all�apparato cardiovascolare e a quello digerente e respiratorio. Alcune correlazioni tra causa (rumore) ed effetto (disturbo) sono ormai assodate:
� Il disturbo aumenta proporzionalmente al tempo di esposizione;
� I tempi di recupero del disturbo sono pi� lunghi di quelli di esposizione al rumore;
� Gli effetti sono maggiori nel riposo e nel sonno;
� Interessa maggiormente i cittadini in et� non lavorativa (bambini ed anziani);
� Non si determina adattamento;
� Si manifesta anche in assenza di disturbi soggettivi;
� Non � influenzato dall�atteggiamento motivazionale positivo o negativo.
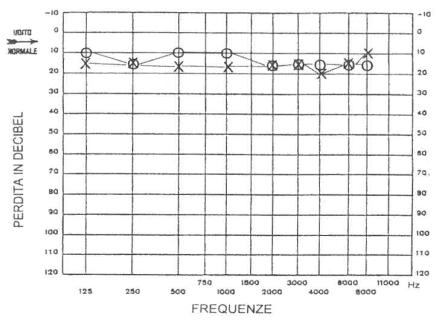
Figura
9: Esempio di tracciato audiometrico normale.
In ambito lavorativo gli effetti uditivi del rumore sono di tipo diverso e sono rappresentati essenzialmente dall'ipoacusia da rumore, patologia determinata dall'esposizione ad elevate intensit� di rumore. L'ipoacusia da rumore di natura professionale � certamente la malattia pi� frequentemente indennizzata dalle compagnie assicuratrici.
Si possono distinguere tre tipi di disturbo arrecato dal rumore:
ΠEffetti
nocivi sull�organo dell�udito
����� Il danno specifico pi� grave dell�organo dell�udito � rappresentato dalla sordit�. La perdita dell�udito � un danno permanente (le cellule danneggiate non possono riprodursi) ed � un evento che si verifica in genere in seguito ad esposizione a livelli molto elevati di rumore, per periodi prolungati e dell�ordini di anni. Generalmente si possono raggiungere tali livelli di rumore solo in ambiente lavorativi, pi� rara � la perdita di udito a causa di eventi occasionali (esplosioni, traumi�). La sensibilit� al rumore ha comunque una spiccata variabilit� individuale: mentre alcuni individui sono in grado di tollerare alti livelli di rumore per lunghi periodi, altri nello stesso ambiente vanno rapidamente incontro ad una diminuzione della sensibilit� uditiva (ipoacusia). Non esiste una cura per l'ipoacusia da rumore e, considerata la non facile applicazione delle protesi, l'unico rimedio � rappresentato dalla prevenzione.
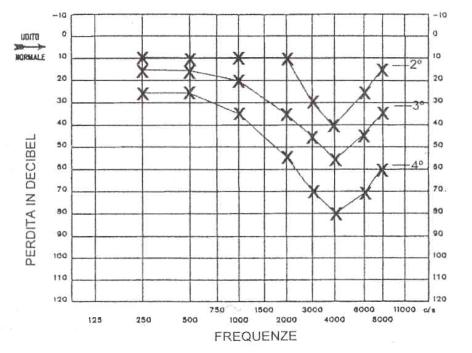
Figura
10: Tracciati audiometrici caratteristici di tre stadi evolutivi del danno
uditivo da rumore.
Si distinguono due tipi di ipoacusia: da trauma acustico cronico e da trauma acustico acuto.
���� Nel primo caso vediamo come
si manifesta il deficit uditivo da un punto di vista sintomatologico. Dopo
alcuni giorni dall'inizio di un lavoro rumoroso, soprattutto alla fine della
giornata lavorativa, possono comparire fischi o ronzii alle orecchie con
sensazione di orecchio pieno, lieve cefalea, senso di intontimento.
Successivamente questi sintomi tendono a scomparire tanto che il lavoratore
esposto ha l'impressione di abituarsi al rumore. Esaurita la resistenza
dell'apparato uditivo, si assiste ad un progressivo peggioramento della soglia
uditiva; il lavoratore non sente pi� il ticchettio dell'orologio e lo squillo
del telefono (deficit per i suoni con frequenze alte). Successivamente il
lavoratore prova difficolt� ad udire la voce dei familiari e dei colleghi di
lavoro e chiede loro di parlare a voce pi� alta, ha bisogno di alzare il volume
della radio e della televisione per comprendere bene le parole (deficit per i
suoni con frequenze pi� basse). Il deficit uditivo fino a questo punto
instauratosi � irreversibile e nella maggioranza dei casi non evolutivo una
volta cessata l'esposizione a rumore. Perdurando l'esposizione a rumore e senza
mezzi di protezione il deficit progredisce fino a che si raggiunge a distanza
di qualche anno o di molti anni la sordit�.
���� Nel caso di ipoacusia da rumore acuto la patologia � la seguente:
���� si instaura dopo esposizione ad un fronte sonoro di elevata intensit� e di breve durata. � frequentemente monolaterale in quanto il capo fa da schermo all'orecchio controlaterale. Si pu� verificare la rottura della membrana timpanica e le lesioni possono interessare sia l'orecchio medio che l'orecchio interno.
��� �Pur tenendo
conto della variabilit� individuale, esistono livelli di rumore che possono
essere ritenuti sicuri: generalmente nei soggetti esposti a livelli inferiori a
75 dB(A) non compaiono disturbi all'udito. Possono verificarsi i primi danni
solo a seguito di un'esposizione a 75 dB(A) per 8 ore al giorno per 40 anni.
� ��Effetti
extrauditivi psicosomatici
����� Quando avvertiamo un rumore fastidioso, la prima reazione � quella di�� individuarne la sorgente e, se possibile, evitare il disturbo. In numerose�� occasioni questo non � possibile, per cui l'organismo rimane esposto ad un� agente che gli � nocivo. Ci� determina l'instaurarsi di una condizione stressante: il rumore � il pi� noto e studiato fattore di stress fisico dell'ambiente.Esso determina, come gli altri fattori di stress, una serie di reazioni di difesa (modificazioni del ritmo del respiro e accelerazione della frequenza cardiaca) e se lo stimolo permane a lungo o se le capacit� di difesa dell'organismo vengono meno, possono verificarsi vere e proprie malattie psicosomatiche: disturbi all'apparato cardiovascolare (aumento della pressione e del battito cardiaco), gastroenterico (aumento della secrezione acida dello stomaco, aumento della motilit� intestinale), respiratorio (aumento della frequenza respiratoria) e del sistema nervoso centrale. Tali disturbi vengono indicati come effetti extrauditivi del rumore proprio perch� interessano altri apparati dell'organismo. A seconda della reattivit� dei singoli soggetti gli effetti si possono manifestare gi� per livelli di rumore inferiori ai 70 dB(A), tuttavia possono comparire anche a seguito di stimolazioni molto lievi. Considerando che i livelli di rumore urbano generalmente sono compresi tra i 40 e gli 80 dB(A) � comprensibile la rilevanza di insorgenza di effetti extrauditivi tra la popolazione. Va considerato che l'abitudine ad un certo tipo di rumore non salva chi lo subisce dai danni fisiologici che provoca.
Ž Effetti
generali di disturbo
Anche per
livelli molto bassi e per esposizioni brevi possono verificarsi condizioni di
alterazione della stato di benessere. Il rumore pu� disturbare il riposo, il
sonno e la comunicazione degli esseri umani, come singoli e come comunit�. Le
interferenze con le varie attivit� umane, la ridotta comprensione delle parole,
i disturbi del sonno e del riposo, le interferenze sull'attenzione, sul
rendimento e sull'apprendimento determinano condizioni che possono ostacolare
le attivit� di relazione e in generale peggiorare la qualit� della vita. E'
stato identificato nell'esposizione ad un livello sonoro continuo equivalente
nell'arco delle 24 ore non superiore a 55 dB(A) il limite compatibile per la
buona salute dei cittadini.
Analisi spettrale
Quando abbiamo a che fare con un suono complesso non siamo nel caso semplice del suono puro, in cui con una precisa legge sinusoidale riusciamo a descrivere completamente il segnale. Per un suono complesso non � facile analizzarne il contenuto energetico, si ricorre allora all�analisi spettrale. Questa utilizza un sistema costituito da un microfono, un amplificatore, un filtro, o meglio un banco di filtri ed un voltmetro tipo Root Mean Square (RMS). Come filtro posso usare, ad esempio, la curva �A�, in modo da avere un guadagno variabile per ogni frequenza ed avere una misurazione in dB(A), o un filtro passa-banda che permette di far passare solo una certa banda di frequenze, relativamente stretta e centrata sulla frequenza che mi interessa studiare,� e annulla il contributo delle frequenze� al di fuori della banda passante. Il pi� delle volte comunque si usa un banco di filtri.
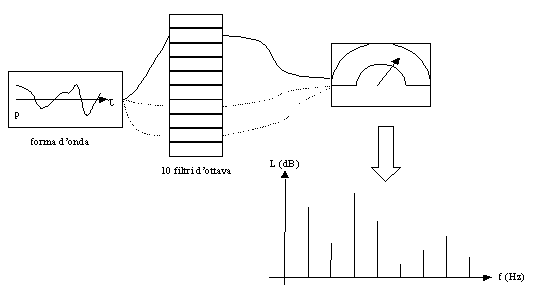
Figura
11: Analisi spettrale con un banco di filtri d�ottava.
Volendo rappresentare un filtro passa-banda non ideale esso � costituito da una zona di guadagno pari pressoch� a 0 dB detta banda efficace Df, e da due zone di forte attenuazione ai lati di Df in cui il guadagno cala velocissimamente. I punti f1 e f2 che delimitano la banda efficace sono dette frequenze di taglio esse sono a met� energia rispetto alla frequenza di centro banda fc (G(fc) = 0) e per definizione G(f1) = -3dB = G(f2).
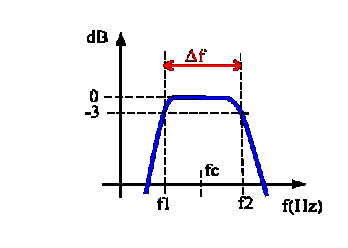
Figura
12: Filtro passa-banda.
Se uso pi� di un filtro consecutivo, questo deve incrociarsi col successivo per legge a �3 dB. Cos� se ho un suono di 90 dB che cade proprio nel punto di incrocio di due filtri: il primo filtro mi misura 87 dB ed il secondo, nello stesso punto, pure 87 dB. Sommando i dB su tutto lo spettro riottengo il valore 90 dB di origine.
Nell�analisi spettrale ci sono 2 tipi di filtri:
i. Filtri ad ampiezza costante;
ii. Filtri ad ampiezza percentuale costante.
Per i filtri del primo tipo ciascuna banda ha sempre la stessa ampiezza. Se per esempio scegliamo 100 Hz come ampiezza di banda ci� vuole un banco da� 200 filtri per coprire tutto il campo dell�udibile 20-20000 Hz.
I filtri del secondo tipo sono i pi� usati. Da un punto di vista fisiologico, come in termini di ampiezza la risposta dell�uomo � proporzionale al logaritmo dell�ampiezza del segnale, cos� in termini di frequenza la risposta � proporzionale al logaritmo della frequenza, ma non si misura in dB bens� si usa il concetto musicale di ottava. Un ottava � un raddoppio di frequenza; in musica infatti un fa di una ottava ha frequenza doppia rispetto al fa dell�ottava precedente e cos� per uno qualsiasi dei 12 semitoni (note) di un ottava. In musica si � unanimi sul fatto che il passaggio da un�ottava alla successiva comporti un raddoppio di frequenza , ma non si sa bene come le bande di ottave stesse si collocano nella gamma di frequenze percepibili. In acustica invece lo IEC (International Electrotechnical Commission) ha normalizzato le bande d�ottava fornendo dei precisi valori di centro banda e dei punti di incontro fra una banda e la successiva.
Tabella 3:
Frequenze di centro banda d�ottava, standard IEC.
|
fc1 (Hz) |
fc2 (Hz) |
fc3 (Hz) |
fc4 (Hz) |
fc5 (Hz) |
fc6 (Hz) |
fc7 (Hz) |
fc8 (Hz) |
fc9 (Hz) |
fc10 (Hz) |
|
31,5 |
63 |
125 |
250 |
500 |
1000 |
2000 |
4000 |
8000 |
16000 |
�
In un�ottava il limite inferiore (f1), quello superiore (f2), e la frequenza di centro banda (fc) verificano le seguenti relazioni:
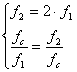 �� risolvendo ho:�
�� risolvendo ho:� 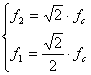
Se ad esempio la fc = 1 kHz, allora f1 = 707 Hz e f2 = 1414 Hz e per la successiva ottava f 3 = f2� = 1414 Hz e f4� =2828 Hz.
L�analisi in filtri d�ottava pu� essere accettabile in campo rumoristico ma � grossolana per calcolare ad esempio la risposta di un altoparlante, in cui � necessaria un�analisi con pi� risoluzioni in frequenza, cio� con pi� filtri pi� stretti. Si usa in questi casi una analisi in frequenza in bande di frazioni di ottava (1/3, 1/6, 1/12, 1/24, ecc.); se si vogliono le relazioni tra i limiti di sottobanda f1 e f2 e si chiama con N il numero di parti in cui suddivido un�ottava ho:
![]() ,� e in generale:
,� e in generale: ![]() �con i = 1, 2, �, N+1.
�con i = 1, 2, �, N+1.
Per calcolare le frequenze di centro banda nelle varie sottobande uso la relazione:
![]()
Cos� se ho un N = 12, cio� in dodicesimi di ottava, per un suono a 1 kHz:
![]() ,� per cui le
frequenze di taglio sono:
,� per cui le
frequenze di taglio sono:
|
f1 (Hz) |
f2 (Hz) |
f3 (Hz) |
f4 (Hz) |
f5 (Hz) |
f6 (Hz) |
f7 (Hz) |
f8 (Hz) |
f9 (Hz) |
f10 (Hz) |
f11 (Hz) |
f12 (Hz) |
f13 (Hz) |
|
707 |
749 |
793,6 |
840,8 |
890,4 |
943,3 |
999,4 |
1058,9 |
1121,8 |
1188,5 |
1259,1 |
1334,6 |
1414 |
Tabella
4: Frequenze di taglio per le bande di 1/12 d�ottava di un suono a 1 kHz
Quella in dodicesimi d�ottava e la risoluzione che meglio approssima le capacit� dell�orecchio umano normale. Una persona otologicamente normale � infatti in grado di arrivare a percepire fino ad una nota di differenza fra due suoni simili, per frazioni d�ottava inferiori non si riescono a cogliere differenze. Nella realt� l�analisi in frequenza ad ampiezza percentuale costante pi� usata � di un terzo d�ottava.
Con N = 3, ![]() , per cui se fc = 1 kHz:
, per cui se fc = 1 kHz:
�
|
f1 (Hz) |
f2 (Hz) |
f3 (Hz) |
f4 (Hz) |
|
707 |
890,8 |
1122,3 |
1414 |
Tabella 5:
Frequenze di taglio per bande di 1/3 d�ottava a 1 kHz.
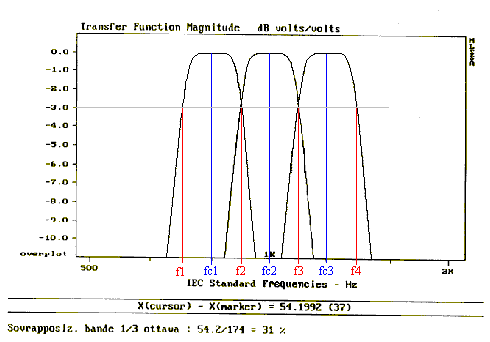
Figura 13:
Filtro di banda di 1/3 d�ottava.
Le frequenze di centro banda in questo caso sono:
![]() �e nominalmente
�e nominalmente ![]()
![]()
![]() e nominalmente
e nominalmente ![]()
Tabella 6: Frequenze nominali per filtri di 1/3 d�ottava per tutto lo spettro udibile.
|
fc1 (Hz) |
fc2 (Hz) |
fc3 (Hz) |
fc4 (Hz) |
fc5 (Hz) |
fc6 (Hz) |
fc7 (Hz) |
fc8 (Hz) |
fc9 (Hz) |
fc10 (Hz) |
fc11 (Hz) |
fc12 (Hz) |
fc13 (Hz) |
fc14 (Hz) |
fc15 (Hz) |
|
25 |
31,5 |
40 |
50 |
63 |
80 |
100 |
125 |
160 |
200 |
250 |
315 |
400 |
500 |
630 |
|
fc16 (Hz) |
fc17 (Hz) |
fc18 (Hz) |
fc19 (Hz) |
fc20 (Hz) |
fc21 (Hz) |
fc22 (Hz) |
fc23 (Hz) |
fc24 (Hz) |
fc25 (Hz) |
fc26 (Hz) |
fc27 (Hz) |
fc28 (Hz) |
fc29 (Hz) |
fc30 (Hz) |
|
800 |
1k |
1250 |
1,6k |
2k |
2,5k |
3,15k |
4k |
5k |
6,3k |
8k |
10k |
12,5k |
16k |
20k |
Lo spettro di un suono assume un aspetto grafico molto diverso in base al tipo di rappresentazione. Se utilizzo filtri ad ampiezza percentuale costante si tende ad usare l�asse delle frequenze logaritmico, mentre per filtri ad ampiezza costante l�asse delle frequenze si presta ad una scala lineare. Iniziando dai filtri d�ottava in figura 14 si nota come lo spettro (f scala logaritmica) sia rappresentato con molte componenti a basse frequenze, che invece con una scala lineare risultano compresse in modo da concentrare in un breve intervallo un numero notevole di informazioni (figura 15). Essendo la scala delle ascisse logaritmica ogni tacca verticale individua un margine di taglio di una delle 30 sottobande in cui si divide lo spettro (infatti ho 31 tacche!).
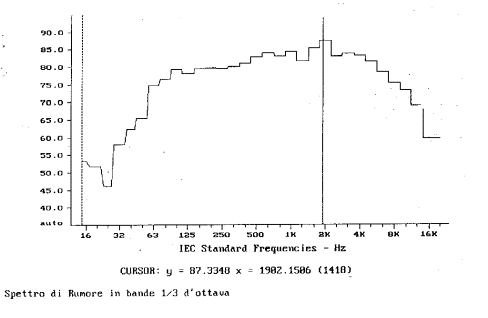
Figura 14:filtro di 1/3 d�ottava con asse delle frequenze
logaritmico.
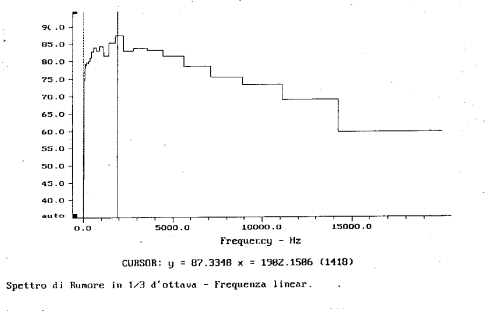
Figura 15:filtro di 1/3 d�ottava con asse lineare delle
frequenze.
Quando passo all�analisi spettrale ad ampiezza costante mi
accorgo subito di una grossa differenza: il livello sonoro segnalato alla
frequenza di 1902 Hz passa da 87 dB circa, per l�analisi con filtri di 1/3
d�ottava, a 67 dB circa per l�analisi ad ampiezza costante. Questo calo si
spiega col fatto che le bande da 1/3 d�ottava sono molto pi� larghe di quelle
costanti e quindi possono far passare frequenze con energia mediamente elevata
anche se non filtro il picco massimo. In ogni caso lo spettro pi� usato, che
approssima meglio il nostro udito, � quello con frequenze in scala logaritmica
e filtro in terzi d�ottava (figura 14).
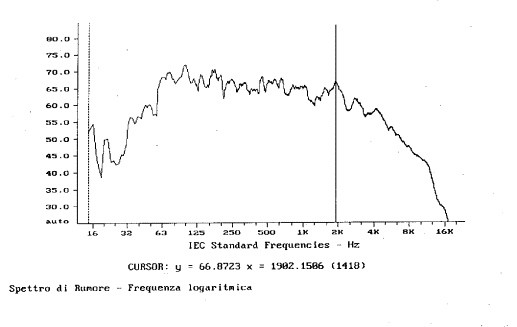
Figura 16: Spettro in banda stretta con frequenza
logaritmica.
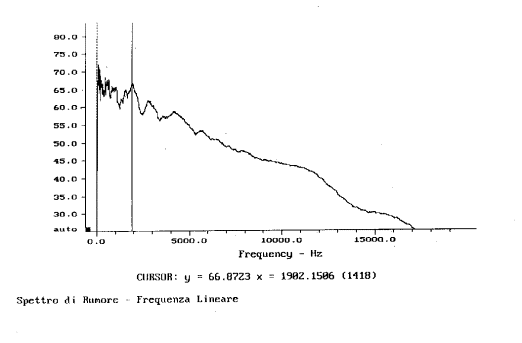
Figura 17: Spettro in banda stretta con frequenza
lineare.
Esercizio
Di un segnale sonoro, tramite analisi spettrale, mi vengono forniti i livelli sonori a diverse frequenze:
|
Frequenza (Hz) |
Livello sonoro (dB) |
Ponderazione �A� |
Livello ponderato (dB(A)) |
|
31,5 |
90 |
-39,4 |
50,6 |
|
63 |
87 |
-26,2 |
60,8 |
|
125 |
80 |
-16,1 |
63,9 |
|
250 |
82 |
-8,6 |
73,4 |
|
500 |
79 |
-3,2 |
75,8 |
|
1000 |
80 |
0 |
80 |
|
2000 |
75 |
+1,2 |
76,2 |
|
4000 |
72 |
+1 |
73 |
|
8000 |
70 |
-1,1 |
68,9 |
|
16000 |
70 |
-6,6 |
63,4 |
Determinare il livello totale in dB e quello ponderato in dB(A).
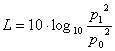 , con p0 = 20 mPa� per definizione di livello sonoro.��
, con p0 = 20 mPa� per definizione di livello sonoro.��
Sapendo che se ho 2 livelli L1 e L2 con
![]() �e�
�e� ![]()
se ne faccio la somma incoerente ottengo:
![]() .
.
Quindi nel mio caso il livello sonoro totale �:
![]()
Se voglio il livello ponderato: