ACUSTICA PSICOFISICA
Presentazione
Il fine di questa lezione è capire il funzionamento del sistema uditivo umano, in modo da prevedere la sensazione uditiva in funzione dello stimolo che la provoca. Conoscere l’udito umano è utile per la progettazione e la costruzione di sistemi acustici dal funzionamento dell’impianto stereo domestico, all’acustica di una grande sala.
La sensazione sonora
La risposta dell’orecchio umano ad uno stimolo sonoro è in generale un fenomeno molto soggettivo: essa infatti dipende da diversi fattori, come il deterioramento del sistema uditivo stesso dovuto a prolungate sollecitazioni. Un segnale sonoro è caratterizzato da due grandezze fondamentali: la pressione, legata all’intensità dell’onda che trasporta il segnale, e la frequenza. Sottoponendo individui otologicamente normali a diversi stimoli sonori, dei quali vengono variate pressione e frequenza, e analizzando le risposte uditive, è possibile tracciare un grafico, detto diagramma di sensazione, che mostri quali suoni sono percepibili dall’uomo.
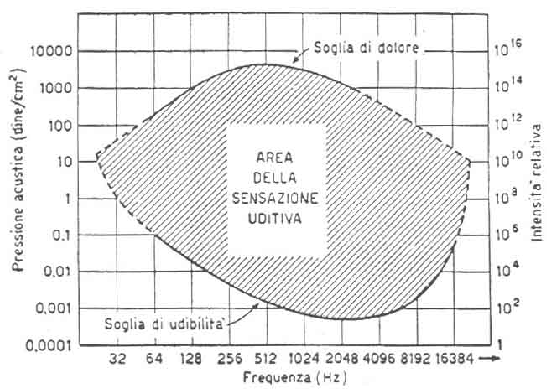
Figura 1: Diagramma di sensazione
Il limite inferiore del grafico, la soglia di udibilità, rappresenta le pressioni minime, alle diverse frequenze, che vengono percepite dall’uomo; il limite superiore, la soglia del dolore, indica la massima intensità sonora che non provoca dolore; fra queste due linee si estende l’area della sensazione uditiva che contiene tutti i suoni udibili.
I ricercatori Fletcher e Munson, utilizzando un diverso approccio al problema, elaborarono negli anni ’30 un diagramma più completo, basato sulle curve isofoniche. Tali curve rappresentano il livello di pressione che deve avere un suono, alle diverse frequenze, per provocare la stessa sensazione. Il procedimento che adottarono era il seguente: un ascoltatore è sottoposto ad un suono puro, generato da un’onda piana sinusoidale con pressione e velocità in fase, e in seguito ad un suono di riferimento con frequenza 1000Hz; regolando l’intensità del suono di riferimento in modo che le due sensazioni corrispondano, si stabilisce a quale curva appartiene la coppia di valori pressione-frequenza del primo suono.
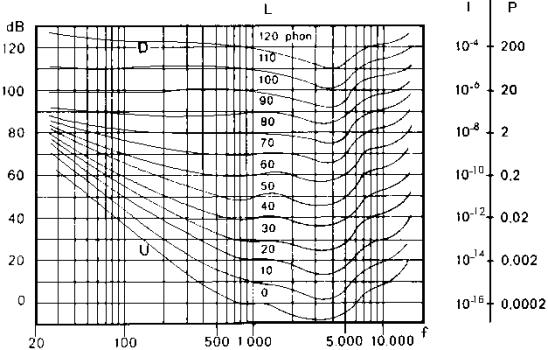
Figura 2: Audiogramma normale
Il nome “audiogramma normale” dato da Fletcher e Munson al grafico ottenuto non è propriamente corretto, perché le condizioni sotto le quali è stato ottenuto (purezza del suono, onde sinusoidali piane) non sono quasi mai confrontabili con la realtà. L’importanza di tale grafico è comunque considerevole, in quanto è utilizzato per valutare le misure effettuate con sistemi che hanno una risposta uguale a tutte le frequenze; su di esso si basano inoltre le normative che stabiliscono per legge il livello sonoro limite al quale può essere sottoposto l’uomo.
La scala dei Decibel
Per comprendere meglio tale grafico è utile definire
una scala per i livelli sonori. Lo scienziato statunitense Graham Bell
(1847-1922) osservò che la sensazione sonora, alla frequenza campione di 1000
Hz, raddoppia se l’intensità del suono che la provoca cresce di un fattore pari
a circa 3.16 @
![]() . Tale valore è naturalmente approssimato, in quanto la
risposta ad una variazione in pressione dipende dalle caratteristiche dell’onda
sonora, ma risulta essere abbastanza preciso. In particolare tale valore
convinse Bell ad usare una scala logaritmica per misurare la sensazione sonora:
scegliendo ad esempio una scala arbitraria alle varie pressioni si avrebbero i
seguenti risultati
. Tale valore è naturalmente approssimato, in quanto la
risposta ad una variazione in pressione dipende dalle caratteristiche dell’onda
sonora, ma risulta essere abbastanza preciso. In particolare tale valore
convinse Bell ad usare una scala logaritmica per misurare la sensazione sonora:
scegliendo ad esempio una scala arbitraria alle varie pressioni si avrebbero i
seguenti risultati
|
Pressione sonora (Pa) |
Sensazione (S) |
|
0.01 |
1 |
|
0.0316 |
2 |
|
0.1 |
3 |
|
0.316 |
4 |
|
1 |
5 |
dove l’aumento di S di un’unità indica il raddoppio della sensazione.
Bell definì quindi la sensazione sonora come:
![]()
utilizzando come
unità di misura per tale grandezza il Bel [B] (dove lg indica il logaritmo in
base dieci). Si può notare come le pressioni usate non siano quelle massime
associate all’onda, ma il valor medio
efficace (RMS) mediato su un periodo, in quanto tale valore è più semplice
da calcolare. La quantità P0
è la pressione di riferimento, fissata al valore ![]() Pa, che corrisponde al più basso suono udibile avente
frequenza 1000 Hz. I valori ottenuti con tale formula corrispondono bene a
quelli trovati sperimentalmente, ma tale scala si rivelò presto troppo grossolana:
è per questo che ancora oggi si usano i suoi sottomultipli, in particolare il Decibel [dB]. Il Decibel non è una vera
e propria unità di misura, ma indica il livello della grandezza al quale è
riferito:
Pa, che corrisponde al più basso suono udibile avente
frequenza 1000 Hz. I valori ottenuti con tale formula corrispondono bene a
quelli trovati sperimentalmente, ma tale scala si rivelò presto troppo grossolana:
è per questo che ancora oggi si usano i suoi sottomultipli, in particolare il Decibel [dB]. Il Decibel non è una vera
e propria unità di misura, ma indica il livello della grandezza al quale è
riferito:
![]()
il risultato di tale espressione è quindi il livello di pressione associato al suono.
Il Decibel viene riferito a qualsiasi grandezza di cui sia necessario avere una scala logaritmica; ad esempio le scale usate per indicare il volume di molti stereo sono espresse in decibel negativi: esse misurano il livello di attenuazione del segnale sonoro originario. Un’altra caratteristica importante del decibel risiede nella sua semplicità pratica ai fini del calcolo. Se, ad esempio, due suoni hanno una differenza nel livello della pressione pari a 6dB, attraverso semplici calcoli si può risalire alla differenza di pressione sonora che li distingue:
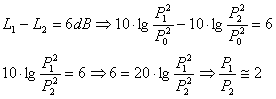
Se il segnale sonoro è trasmesso da un’onda piana
sinusoidale con velocità e pressione in fase, è utile definire un livello per
tutte le sue grandezze caratteristiche. Si definisce quindi il Livello di velocità:
![]()
che indica la velocità
dell’onda sonora rispetto alla velocità di riferimento; quest’ultimo valore si
ricava facilmente ricordando che ![]() :
:
![]()
Il Livello di intensità sonora:
![]()
dove il valore di riferimento è dato da:
![]()
Infine il Livello di densità sonora:
![]()
dove il valore di riferimento è dato da:
![]()
Utilizzando i livelli così definiti per analizzare un’onda piana sinusoidale si ottiene:
![]()
Somma di segnali sonori
Fino ad ora abbiamo analizzato segnali sonori puri caratterizzati da onde piane sinusoidali: nella realtà nessun segnale sonoro si presenta sotto tale forma. Vedremo più avanti che ogni onda, per quanto complicata essa sia, può essere scomposta nella somma di tante onde sinusoidali ognuna con una caratteristica intensità e fase. E’ quindi importante vedere il comportamento dei vari livelli sonori quando vengono sommati due o più toni puri.
La somma di due segnali si dice coerente quando questi sono identici e in fase: in tal caso il segnale risultante ha per pressione la somma delle pressioni delle sorgenti. Il livello totale risulta quindi essere:
![]()
la somma di due segnali a 50 dB risulta quindi di 56 dB.
La somma di due segnali si dice incoerente in tutti gli altri casi: non è detto che le pressioni si sommino aritmeticamente, poiché vi possono essere momenti in cui due picchi dell’onda si sommano o altri in cui un picco e una valle si annullano. In questi casi si ricorre al principio di conservazione dell’energia: l’intensità sonora dell’onda risultante è data dalla somma delle intensità delle sorgenti. Il livello totale risulta quindi essere:
![]()
la somma di due segnali a 50 dB risulta quindi di 53 dB.
Anatomia dell’apparato uditivo
umano
Per capire il motivo per cui la risposta dell’udito umano è diversa a seconda della frequenza del suono, è necessario conoscere la composizione dell’apparato uditivo umano. L’organo dell’udito può essere suddiviso in tre zone specifiche, come si può vedere in figura: l’orecchio esterno, l’orecchio medio e l’orecchio interno.
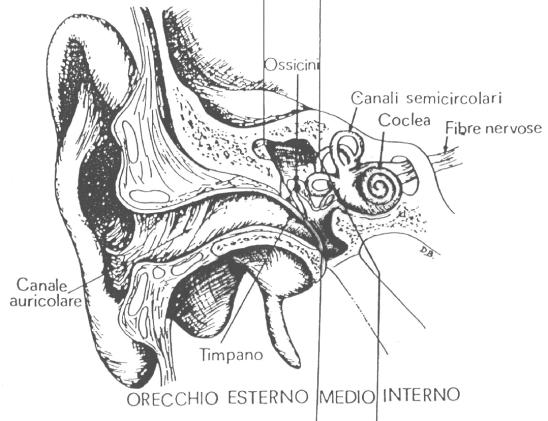
Figura 3: Sezione dell'orecchio umano
L’orecchio esterno comprende il padiglione auricolare, il condotto uditivo e il timpano. Il padiglione auricolare è la parte più esterna del sistema uditivo, la sua funzione è di raccogliere i suoni in modo che attraversino il condotto uditivo. La caratteristica forma a tromba di questo canale provoca il passaggio del suono e una sua leggera amplificazione. Il timpano è una sottile ed elastica membrana, impermeabile ad acqua ed aria, che separa l’orecchio esterno da quello medio, posto alla fine del condotto; quando un suono lo raggiunge ne provoca la vibrazione e questa viene trasmessa alle parti più interne. Il timpano inoltre ha un’impedenza acustica molto piccola, paragonabile a quella dell’aria, in modo che non vi sia una grossa dispersione dell’energia del segnale che trasmette. Questo fatto è aiutato dalla leggera amplificazione provocata dal condotto uditivo: tutto l’orecchio esterno fornisce così la più bassa impedenza acustica possibile e risulta quindi essere un ottimo trasduttore del campo acustico. A causa però della strettezza del condotto stesso il ragionamento appena fatto è valido soprattutto per suoni ad alta frequenza (>1000 Hz), mentre per quelli a basse frequenze la risposta è leggermente minore.
L’orecchio medio è costituito da una cavità interna del cranio, detta cassa timpanica, piena d’aria e contenente una catena di ossicini che hanno il compito di trasmettere la vibrazione del timpano all’orecchio interno; la cassa è collegata alle retrocavità nasali attraverso un condotto detto tromba di Eustachio. Gli ossicini, visibili ingranditi nella figura 4, sono nell’ordine a partire dal timpano: il martello, l’incudine e la staffa. Quest’ultima è appoggiata su un’ulteriore membrana, che separa l’orecchio medio da quello interno, detta finestra ovale.
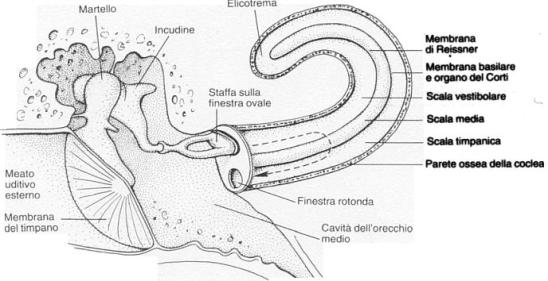
Figura 4: Orecchio medio e Coclea
Poiché l’orecchio interno è riempito da un liquido detto endolinfa caratterizzato da un’impedenza acustica simile a quella dell’acqua, il segnale sonoro trasmesso dall’orecchio medio risulterebbe molto attenuato. Questo problema è risolto dagli ossicini che svolgono la funzione di vere e proprie leve in serie: trasformano il segnale trasmesso dal timpano, caratterizzato da grandi spostamenti ma piccole pressioni, in movimenti della staffa piccoli ma ad alte pressioni. Questo processo non è una vera e propria amplificazione del segnale, esso infatti risulta più intenso ma meno veloce, ma una trasformazione meccanica dell’impedenza.
L’orecchio interno comprende la coclea, il vero e proprio organo dell’udito, e il labirinto, che regola l’equilibrio. La coclea è un tubo a forma di chiocciola suddiviso in due canali (o scale), separati dalla membrana basale: il segnale trasmesso dalla finestra ovale attraversa tutta la coclea, verso il suo centro, lungo il canale vestibolare, in seguito ne esce seguendo in senso opposto il canale timpanico. Durante il passaggio del segnale, la membrana basale si trova sotto sforzo a causa della differenza di pressione presente tra i due canali: questi sforzi vengono registrati dalle cellule cigliate di cui è ricoperta. Queste cellule sono sede di terminazioni nervose e hanno il compito di trasmettere le informazioni al cervello attraverso il nervo acustico.
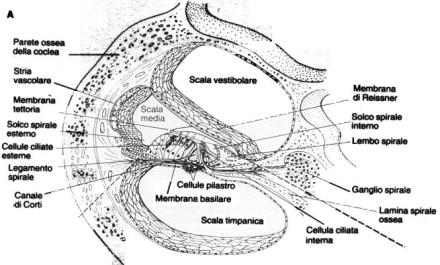
Figura 5: Sezione della coclea
La membrana basale funge inoltre da filtro molto selettivo per quanto riguarda le frequenze percettibili; essa è infatti molto tesa e sottile nelle vicinanze della finestra ovale, mentre diventa sempre più spessa e molle all’avvicinarsi del centro. La tensione della membrana è proporzionale alla frequenza di risonanza a cui lavora: i suoni ad alta frequenza vengono quindi riconosciuti subito, mentre quelli a bassa frequenza devono percorrere tutto il canale vestibolare (ca. 30 mm) prima di essere uditi. Questo fenomeno provoca l’attenuazione dei suoni a basse frequenze e spiega l’andamento delle curve isofoniche del diagramma di Fletcher e Munson.
Un altro aspetto importante che si può osservare nell’apparato uditivo umano risiede nel fatto che il canale di trasmissione del suono è unico e assai limitato: questo fa sì che, quando sono presenti al suo interno troppe informazioni, quelle aventi minore intensità vengono trascurate. Questo accade quando un suono è caratterizzato da diverse componenti, simili in frequenza, ma in cui una prevalga per intensità: la sensazione che riceviamo coincide quindi con la componente più intensa, mentre le altre non sono percepibili. Il fenomeno appena descritto, detto Mascheramento, è alla base delle più moderne tecnologie di compressione dei file audio.
Mascheramento
Come abbiamo visto, la struttura e il funzionamento dell’udito umano comportano la perdita di alcune componenti del suono che percepiamo, a causa del fenomeno chiamato mascheramento. Questo fenomeno può essere visto come unione di due diversi contributi: uno temporale e uno in frequenza.
Il Mascheramento in frequenza è dovuto al fatto che l’udito umano ha una risoluzione limitata in funzione della frequenza: se, ad esempio, consideriamo un tono ad un certo livello e una data gamma di frequenze, la sensazione che ne riceviamo è identica a quella di un tono a livello più basso ma a più ampia banda. In altre parole se l’energia del segnale sonoro è la stessa, a meno di variare banda e intensità, la sensazione che riceviamo è identica. Questo ragionamento è valido all’interno di una certa gamma di frequenze, detta banda critica, caratteristica della frequenza di centro banda; tale comportamento porta a dedurre che il sistema uditivo umano si comporti come un filtro passa-banda. Il grafico in figura 6 mostra le aree di mascheramento per suoni a 60 dB alle varie frequenze: l’unità di misura delle ascisse è il Bark che corrisponde alla larghezza di una banda critica.
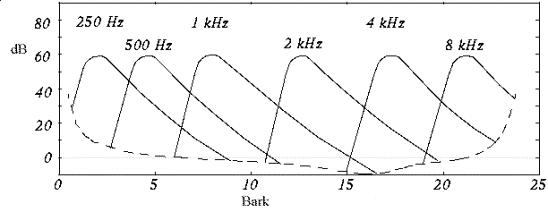
Figura 6: Grafico delle bande critiche
E’ possibile anche scrivere la larghezza delle bande critiche in funzione del centro banda; questi valori, nonostante siano ottenuti adattando valori sperimentali, sono abbastanza attendibili. Per frequenze <500 Hz vale:
![]()
per frequenze >500 Hz vale:
![]()
Il Mascheramento temporale è dovuto al fatto che l’udito umano non è in grado di distinguere suoni deboli se ci raggiungono ravvicinati a un tono, simile in frequenza, ma di livello molto alto. In pratica in presenza di un suono forte è necessario che trascorra un dato intervallo di tempo prima di poter distinguere un suono più debole vicino in frequenza. L’effetto di questo fenomeno è ben sintetizzato dal grafico in figura 7:
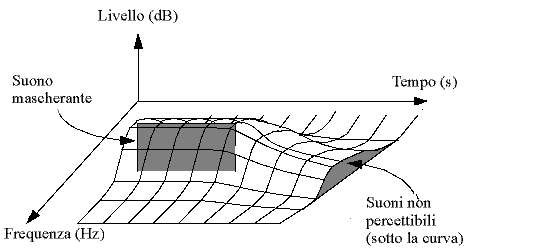
Figura 7: Mascheramento temporale
Il grafico è ottenuto riproducendo un suono con frequenza e livello fissi (il tono mascherante), più un tono di prova di cui si variano frequenza e livello in modo che non venga udito; togliendo il tono mascherante e, dopo un certo ritardo, anche il tono di prova, si regola il ritardo fino al valore più basso per il quale si manifesta il mascheramento.
Compressione sonora
L’archiviazione e la diffusione della musica in
formato numerico è una delle più recenti e sviluppate applicazioni
dell’acustica psicofisica. Esistono due diverse procedure di archiviazione
della musica: la prima, la rappresentazione “senza perdite”, è utilizzata
fondamentalmente nei CD audio e si sta espandendo verso una sempre maggiore
qualità del segnale immagazzinato; la seconda, la compressione sonora, è
utilizzata per la trasmissione via Internet e per l’archiviazione di musica su
supporto dati, come ad esempio l’MP3, e si sta espandendo verso una sempre
maggiore riduzione del flusso di dati audio senza
udibili perdite di qualità. Lo standard CD, che ha una risoluzione dei campioni
di 16 bit ed una frequenza di campionamento di 44,1 kHz, genera un flusso di
1,4 Mbit per un secondo di suono stereo: è evidente come risulti difficile
immagazzinare o trasmettere segnali sonori di tali dimensioni, da qui la
nascita e l’espansione della compressione sonora. Il più diffuso standard di
compressione del suono è senza dubbio quello generato dall’MPEG (Moving
Picture Experts Group), un gruppo che lavora su standard per la codifica di
immagini in movimento e dell’audio.
La compressione sonora si
basa sul fenomeno del mascheramento: tutte le componenti di un suono che
l’udito umano non riesce a percepire vengono scartate. In questo modo si ha
un’effettiva perdita di informazioni, con relativo guadagno nelle dimensioni
occupate dal file sonoro, ma la qualità sonora non ne risente, almeno dal punto
di vista della sensazione umana. In pratica lo scopo non è quello di restituire
il segnale originale intatto, ma piuttosto quello di assicurare che il segnale
di uscita suoni uguale al primo per un ascoltatore.
Basandosi su questa
filosofia sono stati creati i più importanti standard di compressione,
raggiungendo rapporti qualità-dimensioni molto elevati. Le caratteristiche
degli standard creati dall’MPEG sono sintetizzate nella seguente tabella:
|
Livello
di compressione |
Standard
MPEG |
Caratteristiche |
|
1 : 4 |
Layer
1 |
384
kb per secondo |
|
1 : 6 – 1 : 8 |
Layer
2 |
256
– 192 kb per secondo |
|
1 :10 – 1 : 12 |
Layer
3 (MP3) |
198
– 112 kb per secondo |
E’ interessante osservare
come l’algoritmo di compressione alla base dell’MP3 sfrutti appieno i “difetti”
del nostro apparato uditivo:
·
un banco di filtri scompone
il segnale in 32 bande di frequenza, che approssimano le bande critiche;
·
seguendo il modello
psicoacustico si determina un fattore di mascheramento per ciascuna banda, per
fare questo si confrontano i livelli delle bande adiacenti: il fattore di
mascheramento coincide con il massimo suono che sarebbe mascherato.
·
se il livello di una banda è
minore del fattore di mascheramento, l’intera banda non viene codificata;
·
si calcola il numero di bit
necessario per codificare ciascuna banda, in modo che il rumore introdotto
dalla quantizzazione in bit sia minore dell’effetto di mascheramento;
·
si crea lo strema audio.
Filtri di ponderazione
Il livello sonoro misurato da uno strumento con una risposta lineare nel campo delle frequenze udibili mal si correla con la risposta soggettiva degli esseri umani allo stesso rumore. Questo perché l’orecchio umano percepisce i suoni secondo una scala logaritmica e in funzione della loro frequenza. Per rimediare a questo fatto si è pensato di introdurre nei misuratori di livello sonoro una ponderazione dei valori misurati in funzione della frequenza, in modo da avvicinarsi alla valutazione non lineare compiuta dagli esseri umani. In particolare, si è notato che prendendo alcune curve isofoniche e ribaltandole si potevano ottenere dei filtri di ponderazione in frequenza fatti in modo che ad una soglia di sensazione più alta corrispondesse una ponderazione più penalizzante.
La curva di ponderazione A è risultata quella in media meglio correlata con la risposta soggettiva umana a rumori generici a larga banda; questo fatto, unito alla facilità di una misurazione fonometrica in dB(A), ha portato all'adozione della curva A in molte norme e leggi nazionali ed internazionali. Quando però il rumore ha forti componenti tonali o è di tipo impulsivo la curva A non da una valutazione adeguata e viene quindi usata la curva C, la cui risposta è misurata in dB(C).
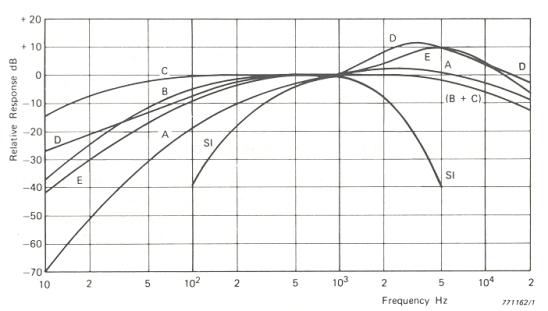
Figura 8: Principali curve di ponderazione
Il filtro A è solitamente usato a valle dei microfoni per misurare i valori efficaci medi e stimare la risposta effettiva dell’orecchio umano. Il filtro C è invece usato per misurare i massimi di picco di suoni forti e impulsivi: in particolare la normativa CEE stabilisce per legge il valore massimo di picco per l’uomo in
Lp,max,peak=130 dB(C)
Perdita uditiva
Con l'incremento dello sviluppo tecnologico, una particolare attenzione merita lo studio dei danni provocati sull'uomo dal rumore, con lo scopo di attuare sistemi preventivi che annullino, o quantomeno riducano al minimo, i suoi effetti. I danni al sistema uditivo possono essere fondamentalmente di due nature diverse: o causati da una breve esposizione a suoni molto intensi (@130 dB), oppure da un’esposizione prolungata a livelli sonori medio-alti (90 – 100 dB).
L’esposizione per poche ore a suoni molto intensi può provocare, a causa dell’elevata sollecitazione meccanica dell’apparato uditivo, un temporaneo malfunzionamento dell’organo intero. Gli effetti sono quindi molteplici, oltre a una temporanea incapacità di percepire altri suoni (mascheramento), possono presentarsi perdita dell’equilibrio, nausea e labirintite. Tali effetti risultano diradarsi nel tempo secondo una legge esponenziale che dipende dall’intensità e dalla durata dell’esposizione; se tali valori superano però una soglia critica si possono presentare danni permanenti: in genere si perde sensibilità per quei suoni caratterizzati da frequenze simili a quello che ha provocato il danno.
Di maggiore interesse sono le patologie provocate dall’esposizione prolungata ad alti livelli sonori: questo è il problema a cui vanno incontro gli operai che lavorano 8 ore al giorno a contatto con attrezzature rumorose. I sintomi provocati sono di tipo soggettivo e variano nel tempo. Nei primi giorni di esposizione si possono presentare acufeni (fischi dovuti a danni al sistema uditivo) e stanchezza generalizzata; col tempo tali disturbi spariscono a causa dell’adattamento. Successivamente, il danno diventa irreversibile e si presentano perdite di sensibilità acustica per suoni di frequenza vicina ai 4000 Hz: si ha quindi uno spostamento della soglia uditiva. Il grafico in figura 9 indica lo spostamento in decibel della soglia uditiva di individui soggetti ad esposizione prolungata per diverse quantità di tempo.
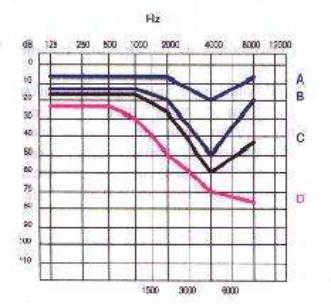
Figura 9: Perdita di udito in ambiente rumoroso
La causa per cui la perdita uditiva maggiore è situata intorno ai 4000Hz, risiede nel fatto che l’organo uditivo umano,in particolare la coclea, è più sensibile a tali frequenze. Tale alta sensibilità è dovuta al fatto che la maggior parte delle componenti della voce umana è caratterizzata da tale frequenza.
In particolare sono le consonanti ad essere caratterizzate dalle alte frequenze, mentre le vocali da quelle più basse (ca. 400Hz). Un individuo affetto quindi da tali lesioni al sistema uditivo, la cosiddetta sordità da rumore (in Italia è presente in ben 2.5 milioni di persone, circa il 5% della popolazione totale), ha quindi la facoltà di sentire la voce umana, ma non riesce a comprendere ciò che gli viene detto.